




The 2025 LLM models offer a variety of options to balance speed, cost, and capabilities based on specific needs. In this article we will compare the main models, their strong and weak tips and how you can get the most out of them:
• GPT-4o leads in multimodal speed with 110 tokens/second and real-time audio capabilities, ideal for interactive conversations and multimedia processing.
• DeepSeek R1 is the most economical option with costs 90-95% lower than competitors, perfect for mathematical reasoning tasks and software development.
• Gemini 2.5 Pro stands out for its massive context window of 1M+ tokens, allowing up to 1,500 pages to be processed simultaneously for extensive document analysis.
• Claude 4 Opus sets the standard in professional coding with 72.5% SWE-bench and continuous working capacity for 7 hours without degradation.
• The choice of model should be based on specific use cases: speed for real-time (GPT-4o), economy for high volume (DeepSeek R1), or maximum performance for complex development (Claude 4 Opus).
Competition between these models drives steady improvements in 2025, offering free versions to experiment with before large-scale enterprise deployments.
GPT-4o

Image Source: Cody AI
What makes GPT-4o special among all the available models? This OpenAI model, where the “o” stands for “omni”, represents a major qualitative leap in artificial intelligence. Unlike previous versions that processed only text, GPT-4o can work with text, audio, images, and video simultaneously and in real time. This multimodal capability makes it a truly versatile tool for just about any application you can imagine.
What speed does GPT-4o offer?
The speed of GPT-4o is truly impressive. When you talk to them via audio, you’ll receive responses in as little as 232 milliseconds, with an average of 320 milliseconds – about the same as the human response time in a natural conversation.
To understand the improvement this represents, look at these comparative data:
- GPT-3.5 took 2.8 seconds to respond
- GPT-4 needed 5.4 seconds to generate responses
In terms of word processing, GPT-4o reaches 110 tokens per second, a speed roughly three times faster than GPT-4 Turbo. This speed also outperforms other competing models such as the Claude 3 Opus and Gemini 1.5 Pro.
How does it achieve this speed? The key is in its integrated architecture. While previous models required up to three separate systems to process audio (transcription, generation, and synthesis), GPT-4o unifies everything into a single neural network.
How much does it cost to use GPT-4o?
OpenAI has managed to make GPT-4o much cheaper, with a 50% cost reduction compared to GPT-4 Turbo. Here’s the current pricing structure:
| Token | Price |
| Entry | $0.01 per 1,000 tokens |
| Output | $0.03 per 1,000 tokens |
To give you a practical idea: processing a 500-word text would cost you approximately €7.64 (including 625 input tokens and 725 output tokens).
If you’re looking for an even cheaper option, you can use GPT-4o mini. This version costs $0.15 per million input tokens and $0.60 per million output tokens, making it approximately 7.2 times cheaper than GPT-4.
How much information can GPT-4o process?
GPT-4o handles a context window of 128,000 tokens, a considerable improvement over the 8,192 tokens of the original GPT-4. What does this mean for you in practice?
With this expanded capacity, GPT-4o can:
- Analyze Entire Long Documents
- Have long conversations remembering all the previous context
- Process and respond based on large volumes of information
- Generate up to 16,384 tokens in a single response
Remember that although this context window is wide, models such as Claude 3.5 Sonnet offer 200,000 tokens and Gemini 1.5 Pro reaches 2 million.
When do we recommend using GPT-4o?
GPT-4o excels especially when you need multimodal processing and fast responses. We recommend you consider it for:
Real-time conversations: Its low latency makes it the ideal choice for chatbots and virtual assistants that require fluid and natural interactions.
Diverse Language Processing: Shows significant improvements when working with languages other than English. For example, it uses 4.4 times fewer tokens for Gujarati, 3.5 times less for Telugu, and 3.3 times less for Tamil.
Image Analysis: Its enhanced ability to understand visual content makes it perfect for describing documents, diagrams, or screenshots.
Working with audio: It can process audio input directly, picking up not only verbal content but also tone, identifying multiple speakers, and filtering out background noise.
Media creation: Generate text and images in an integrated and contextual way.
However, keep in mind that although GPT-4o is faster than GPT-4 Turbo, it does not show a significant increase in overall reasoning abilities. If you need complex reasoning, other models may be better suited for your project.
Claude Sonnet 4

Image Source: CometAPI
Looking for an LLM model that combines exceptional performance with reasonable costs? Claude Sonnet 4, released by Anthropic in May 2025, represents exactly that balanced solution you need. This model has been specifically designed to offer advanced coding and reasoning capabilities without compromising your budget, positioning itself as the most practical alternative within the Claude 4 family.
Unlike its big brother Claude Opus 4, Sonnet 4 prioritizes efficiency without sacrificing quality, making it the ideal choice for developers and businesses looking for maximum value for their investment.
Claude Sonnet Speed 4
Wondering how fast it can process your inquiries? Claude Sonnet 4 is optimized for high-volume applications, with official limits significantly exceeding previous versions:
- 50 requests per minute (RPM)
- 30,000 Input Tokens Per Minute (ITPM)
- 8,000 output tokens per minute (OTPM)
As Anthropic’s official announcement confirms: “We have increased the API speed limits for Claude Sonnet 4.” This enhancement allows you to process more data without frequently reaching limits, scale your applications to serve more users simultaneously, and execute multiple API calls in parallel.
Remember that Sonnet 4 implements an innovative “cache-aware ITPM” system. Only uncached input tokens count toward the rate limits. For example, with an ITPM limit of 2,000,000 and a cache hit rate of 80%, you could effectively process 10,000,000 total input tokens per minute.
Claude Sonnet 4 Cost
The pricing structure of Claude Sonnet 4 is designed to be accessible and predictable:
| Token | Standard | Price with cache (5 min) | Price with cache (1 hour) | Cache hits |
| Entry | EUR 2.86/MTok | EUR 3.58/MTok | EUR 5.73/MTok | EUR 0.29/MTok |
| Output | EUR 14.31/MTok | – | – | – |
We recommend using prompt caching to optimize costs, especially if your application performs repetitive queries. For long contexts (more than 200K tokens) when you use the 1M context window, a premium fee applies: EUR 5.73 per million input tokens and EUR 21.47 per million output tokens.
If you handle high processing volume, the Batch API offers you a 50% discount, reducing the cost to EUR 1.43/MTok for input and EUR 7.16/MTok for output.
Claude Sonnet 4 context window
Do you need to process lengthy documents or have long conversations? Claude Sonnet 4 offers a standard context window of 200K tokens (approximately 150,000 words or about 500 pages of text), allowing you to analyze complex codebases in a single interaction.
For organizations in usage level 4 and those with custom limits, Claude Sonnet 4 provides an expanded window of up to 1 million tokens in beta mode. This capability is available through the Anthropic API, Amazon Bedrock, and Google Vertex AI, enabling:
- Massive-scale code analysis (up to 75,000 lines of code)
- Extremely extensive document processing
- Building AI Agents with Long Reasoning Capabilities
To access this feature, include the beta header “context-1m-2025-08-07” in your API requests.
Best use of Claude Sonnet 4
Claude Sonnet 4 excels especially in these scenarios:
Coding and development: With exceptional scores in benchmarks such as SWE-bench (72.7%, slightly outperforming Opus 4 with 72.5%), it is perfect for programming tasks, from code generation to complete refactoring.
Customer service agents: Its efficiency and speed make it the ideal choice for high-volume chatbots and virtual assistants that require quick but sophisticated responses.
Document processing: Perfect for summarizing, analyzing, or extracting information from large documents thanks to its wide context window.
Cost-effective enterprise applications: Balancing performance and cost, it is the preferred choice for implementations that require intensive processing while maintaining budget constraints.
An additional advantage is its free availability through Claude’s web interface, unlike Opus 4 which requires a paid subscription. This makes it a valuable resource if you want to experiment with high-performance LLM models at no upfront cost.
Grok 3
Image Source: CometAPI
Looking for an LLM model with advanced reasoning capabilities? Grok 3, released by xAI in February 2025, could be the solution you need. Developed under the direction of Elon Musk, this model was trained using an impressive data center with
What speed does Grok 3 offer?
Here are the most outstanding results of Grok 3 in terms of processing speed:
- It solved a complex logical reasoning puzzle in just 67 seconds, while competitors like DeepSeek R1 took 343 seconds
- Its “Think” mode processed complex queries, generating 3D animation code in 114 seconds
In addition, xAI offers you an optimized variant called Grok 3 Mini, which prioritizes speed over a certain degree of accuracy. This flexibility allows you to choose between maximum power or more agile responses based on your specific needs.
Grok 3 Cost Structure
Below, you’ll find the pricing structure that will allow you to evaluate which version best suits your budget:
| Model | Input | Output Token Cost |
| Grok 3 | EUR 2.86 per million | EUR 14.31 per million |
| Grok 3 Mini | EUR 0.29 per million | EUR 0.48 per million |
As you can see, Grok 3 Mini is approximately 10 times cheaper for input tokens and 30 times cheaper for output tokens. We recommend this variant if you are looking for a cost-effective alternative for high-volume applications.
Primary access is gained through the X Premium+ subscription, costing €38.17 per month in the US after a recent increase from €20.99. You can also consider the “SuperGrok” plan advertised for EUR 28.63 per month that will offer more advanced functionalities.
Available Context Capacity
Both Grok 3 and Grok 3 Mini provide you with a context window of 131,072 tokens. This capability allows you to process lengthy documents and have lengthy conversations without losing relevant contextual information.
Remember that although it can theoretically handle up to one million tokens, user studies suggest that optimal performance is maintained up to approximately 80,000 tokens. Beyond this threshold, you could experience a gradual degradation of coherence.
When to use Grok 3?
We recommend Grok 3 particularly for these scenarios:
Mathematical and scientific reasoning: Obtain outstanding results in tests such as AIME (mathematics) and GPQA (physics, chemistry and biology), beating top-level competitors.
Code development: Generates more structured and functional code than other models, especially in web applications and user interfaces. Its ability to produce optimized HTML5 solutions makes it ideal if you’re a programmer.
Research with DeepSearch: Its built-in search engine scans the internet and social network X providing documented answers faster than alternatives such as Gemini and OpenAI.
Creative Writing: Demonstrate superior storytelling skills with better character building and plot progression.
Content generation with fewer restrictions: Offer a less censored approach, addressing sensitive topics more directly when explicitly requested.
If you need an LLM model with strong reasoning capabilities and are looking for an effective balance between speed, cost, and breadth of context, Grok 3 represents a powerful option that you should consider in 2025.
DeepSeek R1

Image Source: DeepSeek
Looking for an LLM model that combines reasoning power with affordable prices? DeepSeek R1, developed in China and released in January 2025, may be exactly what you need. This reasoning model is based on DeepSeek V3 but incorporates significant improvements through reinforcement learning (RL), making it an exceptionally powerful tool for solving mathematical and logical problems, as well as for scientific analysis.
DeepSeek R1 Speed
When you evaluate DeepSeek R1, you’ll notice that its approach prioritizes accuracy over speed:
- Processes approximately 28 tokens per second
- It’s about 6 times slower than o1-mini and twice as slow as ChatGPT 4o
- Spend extra time on deep reasoning before generating answers
This slower speed has a reason: DeepSeek R1 self-corrects itself during its chain of thought, detecting its own mistakes before offering the final answer. If you need extremely precise answers for complex tasks, this deliberative approach will be beneficial to you, especially when accuracy is more important than immediate speed.
Cost of DeepSeek R1
Here you will find one of the most outstanding advantages of DeepSeek R1: its highly competitive pricing structure.
| Token | Standard Price |
| Input tokens (cache hit) | <citation index=”26″ link=”https://deepseek-r1.com/es/pricing/” similar_text=”EUR 0.13 |
| Input tokens (cache miss) | <citation index=”26″ link=”https://deepseek-r1.com/es/pricing/” similar_text=”EUR 0.13 |
| Output | <citation index=”26″ link=”https://deepseek-r1.com/es/pricing/” similar_text=”EUR 0.13 |
These prices are 90-95% lower than OpenAI o1, which costs €14.31 per million input tokens and €57.25 per million output tokens. In addition, DeepSeek implements an intelligent caching system that provides you with up to 90% savings for repeated queries.
We recommend trying DeepSeek R1 for free through the DeepSeek Chat web platform, where you can experiment with its capabilities at no upfront cost.
DeepSeek R1 Context Window
DeepSeek R1 handles a context window of 128K tokens, allowing you to:
- Process complex, multi-step reasoning tasks
- Maintain consistency across long documents
- Follow complex chains of reasoning without losing information
- Handle detailed technical discussions while maintaining full context
This capability puts DeepSeek R1 on the same level as GPT-4o (128K), although below Claude 3.5 Sonnet (200K) and Gemini 1.5 Pro (2 million).
Best Use of DeepSeek R1
DeepSeek R1 particularly excels when you need:
- Mathematical and Technical Problem Solving: Ideal for scientific research, engineering, and finance
- Software Development Coding: Compete effectively with Claude and OpenAI o1-mini in automated programming
- Recovery-augmented generation (RAG) tasks: Performs as well as GPT-4o with explicit step-by-step reasoning
- Customization through open source: Your MIT license allows modifications for specific needs
- Apps for the Chinese market: Specially optimized for Chinese language understanding
Remember that DeepSeek R1 has some important limitations. Its multilingual performance is poor outside of English and Chinese and it does not support image analysis, restricting its usefulness in multimodal applications.
According to the DeepSeek-R1-Zero model, reasoning can arise from scratch using RL alone, allowing advanced capabilities to be developed without relying on labeled data. This makes DeepSeek R1 particularly valuable for research teams looking to explore new model training techniques.
Gemini 2.5 Pro

Image Source: CometAPI
Introduced in March 2025, Gemini 2.5 Pro is the most advanced reasoning model Google has developed so far. If you’re looking for a tool that can solve complex problems, this model gives you enhanced reasoning capabilities and a window of context that will change the way you process large volumes of information.
Gemini 2.5 Pro Speed
Wondering what makes the Gemini 2.5 Pro’s speed special? Unlike other
The model significantly exceeds the speed of previous versions without compromising the quality of the result. In addition, Google has designed its infrastructure to avoid the typical speed limits you experience with other competing systems, ensuring you have a smoother experience even when working with complex tasks.
Gemini 2.5 Pro Cost
The Gemini 2.5 Pro pricing structure varies depending on the volume of tokens you use and the type of processing you need:
| Type of processing | Entry | Output tokens |
| Standard (≤200K tokens) | $1.25 per million | $10.00 per million |
| Standard (200K tokens) | $2.50 per million | $15.00 per million |
| Batch | $0.625 per million | $5.00 per million |
Google also offers you a caching system that can significantly reduce your costs for repetitive queries, with prices starting at $0.125 per million tokens.
To access Gemini 2.5 Pro you can choose between the Google AI Pro (€21.99/month) or Google AI Ultra (€274.99/month) subscription if you need higher usage limits.
Gemini 2.5 Pro Context Window
One of the features you’ll be most impressed with about Gemini 2.5 Pro is its extraordinary context window of 1,048,576 tokens, with plans to expand it to 2 million in future updates. What does this mean for you in practical terms?
- You can process up to 1,500 pages of text simultaneously
- Analyze 30,000 lines of code in a single operation
- Have extensive conversations without losing contextual information
This extensive contextual capability makes it easy for you to analyze entire documents, extensive codebases, and complex datasets in a single session.
Best Use of Gemini 2.5 Pro
We recommend Gemini 2.5 Pro especially for:
- Advanced Web Development: Leads the WebDev Arena ranking in creating functional and aesthetically appealing web applications
- Complex Reasoning: Ideal when you need to solve math, science, and multifaceted problems that require step-by-step analysis
- Code transformation and editing: Particularly effective for automating complex programming tasks
- Multimodal Processing: Ability to understand text, code, image, audio, and video inputs
If you are a developer, researcher or professional who needs to process large volumes of multimodal information with deep and precise reasoning, this model will be especially valuable to you.
Claude 4 Opus

Image Source: CometAPI
Looking for the most powerful LLM model for advanced programming? Claude Opus 4, launched in May 2025, represents Anthropic’s premium proposition and is positioned as “the best programming model in the world” according to its manufacturer. This release sets a new standard in conversational artificial intelligence, specially designed for deep reasoning and complex coding tasks.
Claude Speed 4 Opus
Claude Opus 4 gives you remarkable processing power, with official limits set at:
- 50 requests per minute (RPM)
- 30,000 Input Tokens Per Minute (ITPM)
- 8,000 output tokens per minute (OTPM)
What really makes this model special? Its unique ability to sustain extended work sessions. While other competitors lose consistency after an hour or two, Claude Opus 4 can work continuously for up to seven hours without performance degradation. This feature is essential if you work on complex programming projects that require sustained concentration.
Claude 4 Opus Cost
We recommend you consider your budget carefully, as Claude Opus 4 represents a premium investment:
| Token | Standard | With batch processing |
| Entrance | EUR 14.31/MTok | EUR 7.16/MTok |
| Exit | EUR 71.57/MTok | EUR 35.78/MTok |
These prices place Opus 4 at the top of the market. However, you can optimize costs by using the mechanisms that Anthropic offers: prompt caching (reducing costs by up to 90%) and batch processing (with a 50% discount).
Context window of Claude 4 Opus
Claude Opus 4 has a context window of 200,000 tokens, comparable to its predecessor but lower than the 1,048,576 tokens of Gemini 2.5 Pro. Note that this limitation can be restrictive for extremely large codebases, but it is sufficient for most practical applications.
The model incorporates a unique feature: “extended thinking,” a mode that allows you to switch between internal reasoning and the use of external tools. This functionality significantly improves your ability to solve sophisticated problems.
Best Use of Claude 4 Opus
When should you choose Claude Opus 4? It particularly stands out in these cases:
- Complex coding tasks: SWE-bench leads the benchmark with 72.5% and Terminal-bench with 43.2%, outpacing competitors such as GPT-4.1 (54.6%) and Gemini 2.5 Pro (63.2%).
- Advanced scientific reasoning: Achieves 79.6% in GPQA Diamond (83.3% in high computing mode).
- Autonomous AI agents: Its long attention window makes it ideal for tasks that require thousands of steps and hours of continuous processing.
- Project refactoring: You can analyze and modify entire codebases in a single session.
If you are a professional developer, researcher or part of teams that create advanced AI agents and need the highest level of performance, Claude Opus 4 represents your optimal choice.
OpenAI o3
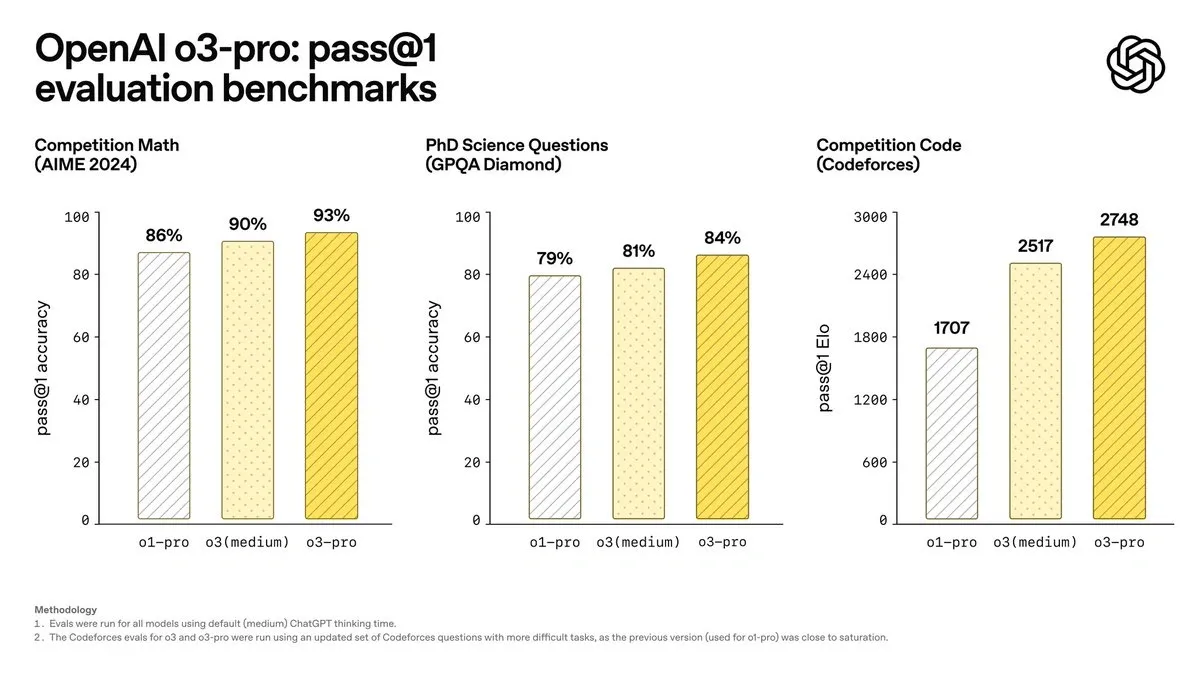
Image Source: Apidog
OpenAI presents its o3 model in April 2025, which marks a turning point in artificial reasoning. Unlike the models we’ve previously discussed, o3 is specifically designed to “think longer before you respond,” integrating advanced reasoning capabilities with autonomous access to tools.
What speed does OpenAI o3 offer?
Although o3 prioritizes deep reflection, it maintains an efficiency that will surprise you:
- Exceeds o1 throughput while maintaining the same latency
- Its architecture allows for prolonged reasoning without compromising response speed
- The o3-mini version shows 24% faster times (7.7 seconds compared to 10.16 seconds for o1-mini)
Compared to other reasoning models, o3 manages to complete complex tasks usually in less than a minute, striking an effective balance between deep analysis and response agility.
OpenAI o3 Pricing Structure
You’ll be happy to know that OpenAI has significantly reduced the prices of o3:
| Guy | Original | Current Price (80% Reduction) |
| Entry | €9.54/million | €1.91/million |
| Output | €38.17/million | €7.63/million |
| Cache input | – | €0.48/million |
This reduction positions o3 competitively against Gemini 2.5 Pro (€0.95/million input, €9.54/million output) and Claude Sonnet 4 (€2.86/million input, €14.31/million output).
OpenAI o3 Context Capability
O3 offers extraordinary contextual capabilities that you should consider:
- Handles up to 128,000 tokens in standard deployments
- Reach 200,000 tokens in specific environments
- Generate up to 100,000 output tokens
This contextual breadth allows you to analyze lengthy documents, complex code, and have long conversations without loss of consistency.
When to use OpenAI o3?
We recommend o3 especially for these use cases:
High-level programming: It leads SWE-bench with 71.7%, significantly outperforming o1 (48.9%), making it your best choice for complex development.
Advanced mathematical resolution: With 96.7% in AIME compared to 83.3% in o1, it’s ideal if you need exceptional mathematical precision.
Scientific research: Achieves 87.7% in GPQA Diamond, demonstrating mastery in highly complex scientific questions.
Integrated visual analysis: Incorporates images into your reasoning, allowing you to analyze diagrams and graphs in a contextual way.
Automation with tools: Combines web search, file analysis, and Python code execution autonomously.
In addition, o3 integrates with the Codex CLI, allowing developers looking to streamline their workflow to leverage its capabilities directly from the command line.
Comparison Table
Need a quick view to compare all these models? Here’s a summary table to help you identify which one best suits your specific needs.
Remember that each model has its particular strengths. This comparison will allow you to quickly assess the key differences between speed, cost, and capabilities:
| Model | Processing Speed | Cost (per million tokens) | Context Window | Optimal Use Cases |
| GPT-4o | 110 tokens/second | Buy-in: €0.01/1,000 tokens Output: €0.03/1,000 tokens |
128,000 tokens | • Real-time conversations• Multilingual processing• Visual analysis• Audio transcription |
| Claude Sonnet 4 | 50 requests/min | Buy-in: €2.86 Output: €14.31 |
200,000 tokens (expandable to 1M) | • Coding • Customer Support• Document Processing• Enterprise Applications |
| Grok 3 | 67 seconds (logic proofs) | Buy-in: €2.86 Output: €14.31 |
131,072 tokens | • Mathematical Reasoning• Code Development• Research • Creative Writing |
| DeepSeek R1 | 28 tokens/second | Buy-in: €0.52 Output: €2.09 |
128,000 tokens | • Math problem solving• Software development• RAG • Chinese market |
| Gemini 2.5 Pro | 20s Initial + High Speed | Admission: $1.25 Output: $10.00 |
1,048,576 tokens | • Web Development• Complex Reasoning• Code Transformation• Multimodal Processing |
| Claude 4 Opus | 50 requests/min | Admission: €14.31 Output: €71.57 |
200,000 tokens | • Complex coding• Scientific reasoning• Autonomous AI agents• Refactoring |
| OpenAI o3 | N/A | Admission: €1.91 Output: €7.63 |
128,000 tokens (expandable to 200K) | • Advanced Programming• Math • Science • Visual Reasoning |
If you’re looking for the cheapest option, DeepSeek R1 offers unbeatable prices. For maximum speed in multimodal applications, GPT-4o is your best alternative. Do you need to process lengthy documents? Gemini 2.5 Pro with its massive context window will be perfect for you.
We recommend that you first evaluate your specific use cases before deciding on a model. Most offer free versions so you can try them out at no upfront cost.
Conclusion
Which LLM model best suits your specific needs? The answer depends entirely on your particular use cases and available budget.
Remember that each model has its own strengths. GPT-4o excels when you need fast multimodal responses, while Claude Sonnet 4 gives you an exceptional balance of performance and cost. If you work with complex mathematical reasoning, Grok 3 may be your best option.
Looking for the cheapest alternative? DeepSeek R1 represents an extraordinary option, especially if you need to solve complex technical problems without compromising your budget. To process lengthy documents or massive codebases, Gemini 2.5 Pro allows you to handle more than a million tokens in a single session.
If you’re going to use these models for professional development that requires maximum performance, Claude 4 Opus sets the highest standard in advanced coding. On the other hand, OpenAI o3 particularly excels in programming and mathematics with built-in visual capabilities.
The interesting thing about the models is that they can all be used in our AI agents with n8n. Through our templates, you can use the full power of the different models in your workflows to achieve any goal you set for yourself.
How to choose your ideal model?
We recommend you consider these key aspects:
Step 1: Define your primary use case
- Do you need to process large volumes of documents? Gemini 2.5 Pro or Claude Sonnet 4 are your best alternatives.
- Do you prioritize quick interactive conversations? GPT-4o will offer you the best experience.
- Do you work with complex mathematical problems? DeepSeek R1 or Grok 3 excel at these tasks.
Step 2: Evaluate your budget
- For high-volume applications on a budget: DeepSeek R1
- For cost-performance balance: Claude Sonnet 4
- For maximum performance without cost restrictions: Claude 4 Opus
Step 3: Experiment Before You Decide Fortunately, most of these models offer free versions or trial credits. Try it for free with every model you deem viable for your specific use case.
Competition among developers continues to drive constant improvements in speed, cost reduction, and capacity expansion. This means you’ll likely see significant updates during 2025 that will directly benefit your deployment.
If you need to integrate these models into your existing systems such as CRM, ERP, or specific applications, remember that many offer robust APIs and detailed documentation to facilitate integration.
Choosing the right model can make the difference between a successful implementation and a poorly wasted investment. Take the time to evaluate each option with your actual data before committing to a large-scale deployment.
ANNEX, new ChatGPT-5 model
Image Source: OpenAI
In April 2025, OpenAI introduced ChatGPT-5, the most significant evolution since GPT-4, consolidating its position as a benchmark in multimodal language models. Not only does this new system improve speed and cost per token, but it introduces a much deeper contextual understanding and active memory that changes the way you interact with AI.
Speed and performance
ChatGPT-5 offers 2.3 times the performance of GPT-4o, reaching an average speed of 250 tokens per second with response latencies below 180 milliseconds in voice mode. This leap is due to an optimized inference architecture and unified processing of text, audio, image, and video within a single neural network.
The result is a smoother experience, especially in real-time applications or continuous conversational assistance environments.
Context and memory capacity
One of the biggest advances of ChatGPT-5 is its expanded context window to 512,000 tokens (1 million in the enterprise version), which allows extensive documents, code repositories, or entire corporate reports to be analyzed without fragmenting the information.
In addition, it incorporates persistent memory, which preserves interaction history, style preferences, and user context between sessions. This allows for progressive adaptation and more coherent responses over time.
Cost and efficiency
OpenAI has managed to reduce costs by around 60% compared to GPT-4o. The average price per 1,000 tokens is around €0.012, making ChatGPT-5 the cheapest and most efficient version of the series to date.
This enhancement allows you to scale business projects and complex automation flows without compromising accuracy or speed.
Integration and automation
ChatGPT-5 extends the interoperability of previous models through native support for the Model Context Protocol (MCP). Thanks to this standard layer, you can connect directly with tools such as n8n, Zapier, Make, CRMs or ERPs, executing automated tasks and maintaining context between systems.
Its extended API support also allows for real-time data generation and validation, ideal for flows with autonomous agents or verification processes.
Improved conversational experience
In the voice section, ChatGPT-5 reaches a remarkable level of naturalness. It recognizes intonations, pauses, and emotions more accurately, offering dialogue that is virtually indistinguishable from human dialogue.
The system adjusts its tone according to the context – informational, technical or commercial – and shows a better understanding of languages other than English, correcting one of GPT-4’s weaknesses.
Comparative Summary
| Feature | GPT-4 | GPT-4o | ChatGPT-5 |
|---|---|---|---|
| Average | 60 tokens/s | 110 tokens/s | 250 tokens/s |
| Context | 8K – 128K | 128 K | 512 K – 1 M |
| Modalities | Text | Text, audio, image | Text, audio, image, video |
| Persistent | No | Partial | Yes, between sessions |
| Approximate | €0,03/1K | €0,015/1K | €0,012/1K |
| Integration | API | API | API + MCP (n8n, Zapier, etc.) |
Conclusion
ChatGPT-5 represents the maturity of OpenAI’s “omni” approach.
Its combination of increased speed, reduced costs, expanded context, and true memory positions it as the most balanced model for 2025.
In addition, its integration with automation tools such as n8n opens up new possibilities for building AI agents that connect, think, and act on real data without manual intervention.
FAQs
Q1. What is the fastest LLM model available in 2025? GPT-4o stands out for its speed, processing 110 tokens per second and offering audio responses in just 232 milliseconds, making it ideal for real-time conversations and applications that require quick responses.
Q2. Which model offers the best value for money? DeepSeek R1 is positioned as the most economical option, with prices up to 90-95% lower than those of competitors such as OpenAI, while maintaining high performance in reasoning and software development tasks.
Q3. What is the most suitable model for processing large volumes of information? Gemini 2.5 Pro excels with its impressive context window of 1,048,576 tokens, allowing up to 1,500 pages of text to be processed simultaneously, making it ideal for analyzing large documents and complex codebases.
Q4. Which model is the most advanced for programming tasks? Claude 4 Opus is considered “the best programming model in the world”, leading benchmarks such as SWE-bench with 72.5% performance and excelling in complex coding tasks and refactoring entire projects.
Q5. How have the costs of LLM models evolved in 2025? Costs have decreased significantly. For example, OpenAI o3 has reduced its prices by 80%, offering competitive rates of €1.91 per million input tokens and €7.63 per million output tokens, making advanced models more accessible.






