


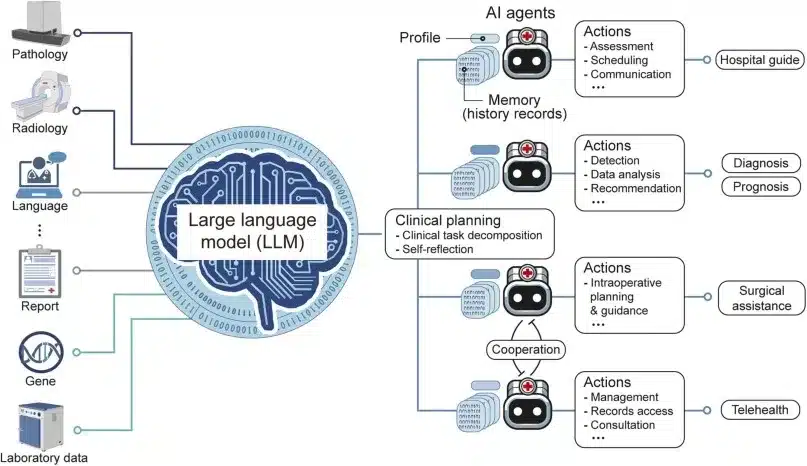
En este artículo aprenderás todo lo que necesitas saber sobre los Modelos de Lenguaje de Gran Tamaño (LLM) de una forma práctica y sencilla. Descubrirás qué son exactamente, cómo funcionan por dentro y cuáles son sus aplicaciones más importantes en 2025. También conocerás los riesgos que debes tener en cuenta y cómo elegir el modelo más adecuado para tus necesidades.
Si alguna vez te has preguntado cómo ChatGPT, Claude o Gemini pueden entender y generar texto casi como un humano, aquí encontrarás las respuestas. Te mostraremos desde los conceptos básicos hasta las tendencias más avanzadas, siempre con ejemplos prácticos que podrás aplicar.
Puntos clave
Los LLM representan una revolución tecnológica que está transformando la forma en que interactuamos con las máquinas y procesamos información. Aquí están los puntos esenciales que debes conocer:
• Los LLM son modelos de IA especializados en lenguaje que utilizan arquitecturas Transformer para procesar billones de parámetros y generar texto similar al humano.
• Su entrenamiento requiere recursos masivos: GPT-3 consumió 1.287 MWh de electricidad y produjo más de 500 toneladas de CO2, equivalente a 600 vuelos transatlánticos.
• Las aplicaciones prácticas incluyen generación de contenido, traducción multilingüe, conversión de código y asistentes virtuales que ahorran 30-90% del tiempo en tareas rutinarias.
• Los principales riesgos son las alucinaciones (2,5-15% de respuestas falsas), sesgos heredados de datos de entrenamiento y vulnerabilidades de privacidad y seguridad.
• El futuro apunta hacia modelos multimodales más eficientes, contextos de hasta 2 millones de tokens y regulación responsable como la nueva ley europea de IA.
La comprensión de estas capacidades y limitaciones te permitirá aprovechar el potencial de los LLM mientras navegas responsablemente por este panorama tecnológico en constante evolución.
¿Qué es un LLM o ‘Large Language Model’?
Imagina un sistema que puede leer millones de libros, artículos y páginas web en cuestión de días, y luego usar todo ese conocimiento para mantener conversaciones, escribir textos o resolver problemas complejos. Eso es exactamente lo que hace un Modelo de Lenguaje de Gran Tamaño.
Un LLM es un tipo de inteligencia artificial especializada en entender y generar lenguaje humano. A diferencia de los programas tradicionales que siguen reglas específicas, estos modelos aprenden patrones del lenguaje analizando enormes cantidades de texto. El resultado es sorprendente: pueden escribir como si fueran personas, traducir idiomas, programar código o responder preguntas sobre prácticamente cualquier tema.
¿Por qué son tan importantes ahora? Porque han alcanzado un nivel de sofisticación que les permite realizar tareas que antes solo podían hacer los humanos. ChatGPT, Claude, Gemini… todos estos nombres que escuchas constantemente son ejemplos de LLM que están cambiando la forma en que trabajamos, estudiamos y nos comunicamos.
¿Qué es un LLM o ‘Large Language Model’?
Definición técnica de LLM
Un Modelo de Lenguaje de Gran Tamaño (LLM, por sus siglas en inglés) es un sistema de inteligencia artificial entrenado con enormes cantidades de texto que puede entender y generar lenguaje humano de forma sorprendentemente natural. Piensa en él como un programa que ha “leído” millones de libros, artículos y páginas web, y ahora puede mantener conversaciones, escribir textos y responder preguntas de manera coherente.
La base técnica de estos modelos son los transformadores, una arquitectura de redes neuronales que funciona como un sofisticado sistema de atención. Imagina que estás leyendo una frase: los transformadores pueden “mirar” todas las palabras al mismo tiempo y entender cómo se relacionan entre sí, en lugar de procesarlas una por una como hacían los sistemas anteriores.
Durante el entrenamiento, estos sistemas aprenden a predecir qué palabra viene después en un texto, desarrollando gradualmente una comprensión profunda de la gramática, el significado y el contexto. Es un proceso de autoaprendizaje donde el modelo descubre patrones lingüísticos sin que nadie le enseñe reglas específicas.
Diferencia entre LLM y otros modelos de IA
¿Te has preguntado qué hace especiales a los LLM frente a otros tipos de inteligencia artificial? La diferencia principal radica en su especialización y enfoque.
Mientras que la IA es un término amplio que incluye cualquier sistema que imita capacidades humanas, los LLM se concentran exclusivamente en el lenguaje. Otros modelos de IA pueden estar diseñados para reconocer imágenes, predecir tendencias de mercado o controlar robots, pero los LLM son expertos únicamente en entender y generar texto.
Las diferencias clave incluyen:
- Especialización en lenguaje: Los LLM dominan tareas como traducir, resumir o escribir, mientras que otros modelos de IA se enfocan en áreas completamente diferentes como visión artificial o análisis de datos.
- Arquitectura específica: Utilizan transformadores optimizados para captar relaciones entre palabras, algo que otros tipos de IA no necesariamente requieren.
- Capacidades generativas: Muchos LLM pueden crear contenido original, aunque la IA generativa abarca más allá del texto, incluyendo imágenes, música y código.
¿Por qué se llaman ‘grandes’ modelos de lenguaje?
El término “grande” no es una exageración publicitaria. Se refiere a tres aspectos que realmente impresionan por su magnitud:
Tamaño de parámetros: Los LLM contienen billones de parámetros, que son como los “ajustes internos” que determinan su funcionamiento. Para darte una idea de la escala, GPT-3 tiene 175.000 millones de parámetros, mientras que Jurassic-1 cuenta con 178.000 millones. Es como si tuvieran millones de pequeñas decisiones programadas en su interior.
Volumen de datos de entrenamiento: Estos modelos han procesado cantidades masivas de texto de internet. Hablamos de Common Crawl con más de 50.000 millones de páginas web y Wikipedia completa con sus 57 millones de artículos. Es más información de la que cualquier persona podría leer en varias vidas.
Capacidad computacional: Entrenar un LLM requiere supercomputadoras trabajando durante semanas o meses. Cada uno de esos billones de parámetros debe ajustarse con precisión, lo que demanda una potencia de cálculo extraordinaria.
Los modelos más destacados que puedes usar actualmente incluyen:
- GPT de OpenAI, conocido por su capacidad de razonamiento y respuestas coherentes
- Claude que puede analizar documentos muy extensos con hasta 100.000 tokens
- Llama de Meta, optimizado para aplicaciones prácticas del mundo real
- Gemini de Google DeepMind, ya integrado en Gmail y otros servicios que probablemente uses a diario
Cada uno tiene fortalezas particulares, pero todos comparten esa característica “grande” que los hace tan potentes para trabajar con lenguaje humano.
Arquitectura de los modelos LLM: cómo están construidos
¿Te has preguntado alguna vez qué hay detrás de la capacidad de ChatGPT para mantener una conversación coherente? En esta sección descubrirás cómo están construidos estos sistemas por dentro. Te mostraremos de forma sencilla los componentes principales que permiten a los LLM entender y generar texto como si fueran humanos.
Recuerda que aunque la arquitectura pueda parecer compleja al principio, comprenderla te ayudará a elegir mejor qué modelo utilizar según tus necesidades.
Redes neuronales profundas y capas de atención
Los LLM funcionan mediante redes neuronales multicapa que imitan, de alguna manera, el funcionamiento del cerebro humano. Piensa en estas redes como una serie de filtros interconectados, donde cada capa procesa y refina la información recibida de la capa anterior.
La diferencia principal con los modelos tradicionales es el número de capas. Mientras que los sistemas antiguos utilizaban una o dos capas, los LLM actuales emplean cientos o incluso miles de capas para procesar la información. Cada nodo de estas capas tiene un peso específico y un umbral que determina si debe activarse y pasar información a la siguiente capa.
Dentro de esta arquitectura, encontrarás tres tipos de capas principales:
- Capas de incrustación: Convierten las palabras en números que el modelo puede entender
- Capas de atención: Ayudan al modelo a identificar qué partes del texto son más importantes
- Capas de alimentación hacia adelante: Procesan toda esta información para generar la respuesta final
Transformers y autoatención
Aquí es donde la magia realmente ocurre. Los Transformers, introducidos en 2017, cambiaron completamente el juego. Esta arquitectura permite que el modelo procese todas las palabras de una frase al mismo tiempo, en lugar de hacerlo palabra por palabra.
El mecanismo de autoatención es el corazón de esta tecnología. Funciona evaluando la relación entre cada palabra y todas las demás palabras del texto. Por ejemplo, en la frase “El perro que está en el parque ladra fuerte”, el sistema entiende que “ladra” se refiere a “perro”, no a “parque”.
Esta capacidad de entender relaciones a larga distancia era muy difícil para los modelos anteriores. Además, al procesar todo en paralelo, el entrenamiento es mucho más rápido y eficiente.
Los Transformers utilizan dos componentes principales: un codificador que entiende el texto de entrada y un decodificador que genera la respuesta. Sin embargo, algunos modelos como GPT utilizan solo la parte decodificadora.
Tokenización y embeddings
Antes de procesar cualquier texto, los LLM necesitan convertirlo en números mediante la tokenización. Este proceso divide el texto en pequeñas unidades llamadas tokens.
El método más utilizado es el Byte Pair Encoding (BPE), que identifica las combinaciones de letras más frecuentes y las convierte en tokens. Esto permite al modelo manejar palabras nuevas, nombres propios e incluso errores tipográficos de forma inteligente.
Una vez tokenizado, cada palabra se convierte en un vector numérico llamado embedding. Estos vectores capturan el significado de las palabras de tal forma que palabras similares tienen números parecidos.
Por último, como los Transformers procesan todo simultáneamente, necesitan saber el orden de las palabras. Para esto utilizan codificaciones posicionales que se añaden a cada embedding. Así el modelo entiende que “María ama a Juan” es diferente de “Juan ama a María”.
Si tienes alguna pregunta sobre estos conceptos técnicos, te recomendamos empezar con los aspectos más prácticos y luego profundizar en los detalles según tus necesidades específicas.
Entrenamiento de un modelo LLM: ¿cuánto cuesta realmente?
Crear un modelo de lenguaje grande no es como instalar un programa en tu ordenador. Es un proceso que consume recursos masivos y que determina si el modelo será útil o no. A continuación, te mostramos todo lo que necesitas saber sobre este proceso.
¿Cómo aprenden los LLM? Dos métodos principales
Existen dos formas principales de entrenar estos modelos, cada una con sus propias ventajas:
Preentrenamiento autorregresivo: Los modelos como GPT funcionan como un sistema que completa frases. Aprenden a predecir cuál será la siguiente palabra basándose en todas las palabras anteriores. Es como cuando escribes en tu móvil y te sugiere la siguiente palabra.
Preentrenamiento enmascarado: Modelos como BERT utilizan un método diferente. Se ocultan palabras al azar en un texto y el modelo debe adivinar cuáles faltan. Es como hacer un ejercicio de rellenar huecos.
La diferencia clave es que los modelos autorregresivos solo miran hacia atrás para predecir, mientras que los enmascarados pueden mirar tanto hacia atrás como hacia adelante, obteniendo una comprensión más completa del contexto.
Los costos reales: cifras que te sorprenderán
Entrenar un LLM es extraordinariamente caro. Para que tengas una idea clara:
Consumo energético masivo: GPT-3 necesitó 1.287 MWh de electricidad para su entrenamiento. Esto equivale al consumo anual de más de 100 hogares.
Huella de carbono significativa: El proceso generó más de 500 toneladas métricas de CO2, comparable a 600 vuelos entre Nueva York y Londres o lo que producen 38 hogares españoles en un año completo.
Inversión económica elevada:
- Un modelo de 1.500 millones de parámetros costaba 0,95 millones de euros en 2020
- GPT-3 (175 mil millones de parámetros) costó aproximadamente 3,82 millones de euros
- GPT-4 superó los 95,42 millones de euros por su mayor complejidad
Recuerda que estos costos se dividen en dos fases: el entrenamiento inicial consume 20-40% de la energía total pero ocurre una sola vez. La fase de uso continuo puede representar 50-60% del gasto energético a largo plazo.
¿Sabías que generar imágenes consume 2,907 kWh por cada 1.000 operaciones, mientras que generar texto solo necesita 0,047 kWh? La generación de texto es mucho más eficiente.
¿Cómo aprenden sin supervisión humana?
El aprendizaje autosupervisado es la clave del éxito de los LLM. A diferencia de métodos tradicionales que necesitan datos etiquetados manualmente, estos modelos generan sus propias etiquetas a partir de texto sin procesar.
El proceso funciona así: el modelo aprende a predecir partes faltantes del texto o la siguiente palabra en una secuencia. Esto permite entrenar con enormes cantidades de texto de internet sin necesidad de etiquetado manual.
El proceso se divide en dos etapas:
Paso 1: Tareas de pretexto – El modelo aprende representaciones del lenguaje mediante tareas como predecir palabras ocultas o completar secuencias.
Paso 2: Tareas específicas – Las representaciones aprendidas se aplican a tareas concretas como traducción o clasificación de texto.
Existen dos técnicas principales:
- Aprendizaje autopredictivo: El modelo predice partes de datos basándose en otras partes
- Aprendizaje contrastivo: El modelo aprende a distinguir relaciones entre diferentes muestras de datos
Esta metodología permite aprovechar eficientemente los recursos computacionales masivos necesarios para crear LLM cada vez más potentes.
Aplicaciones prácticas de los LLM en 2025
Los LLM ya no son solo experimentos de laboratorio. En 2025, estas herramientas resuelven problemas reales en empresas de todos los sectores. A continuación, te mostramos las aplicaciones más útiles que puedes implementar hoy mismo.
Generación de texto y resúmenes automáticos
¿Necesitas procesar grandes volúmenes de información rápidamente? Los LLM destacan por su capacidad para crear contenido original y resumir documentos extensos manteniendo los puntos clave.
La creación de resúmenes automáticos te permite ahorrar tiempo y recursos significativos al procesar información. Esta funcionalidad es especialmente valiosa para:
- Artículos de investigación y documentación técnica
- Documentos legales y financieros
- Comentarios de clientes y análisis de tendencias
- Informes empresariales y estudios de mercado
Existen dos métodos principales que puedes utilizar. El resumen extractivo identifica y extrae las oraciones más relevantes del texto original, mientras que el resumen abstractivo genera nuevas oraciones que capturan la esencia del contenido. Dependiendo de tus necesidades, puedes obtener desde resúmenes breves hasta análisis detallados.
Las herramientas más avanzadas también proporcionan puntuaciones de clasificación para evaluar la relevancia de las oraciones extraídas e información posicional para ubicar los elementos más importantes.
Traducción multilingüe y conversión de código
Si trabajas con múltiples idiomas o necesitas modernizar código antiguo, los LLM ofrecen soluciones precisas que superan los métodos tradicionales.
Para traducción, estos modelos captan matices culturales y preservan el tono del texto original. El modelo de DeepL supera en calidad a ChatGPT-4, Google y Microsoft, requiriendo significativamente menos revisión: mientras Google necesita el doble de correcciones y ChatGPT-4 el triple para alcanzar la misma calidad.
En cuanto a conversión de código, los LLM han demostrado ser extraordinariamente eficaces para migrar sistemas heredados. La herramienta CodeScribe, por ejemplo, combina ingeniería de prompts con supervisión humana para convertir código Fortran a C++ de forma eficiente.
Los resultados son impresionantes: mientras que antes del uso de LLM se podían convertir 2-3 archivos por día, con estas herramientas la productividad aumenta a 10-12 archivos diarios.
Asistentes virtuales y chatbots empresariales
¿Quieres automatizar la atención al cliente o mejorar procesos internos? Los asistentes potenciados por LLM mantienen conversaciones fluidas, comprenden preguntas complejas y se adaptan al estilo de cada usuario.
Recuerda que existe una diferencia importante: los asistentes de IA son reactivos y realizan tareas bajo demanda, mientras que los agentes de IA son proactivos y trabajan autónomamente para lograr objetivos específicos.
Un estudio entre 167 empresas identificó que el servicio de atención al cliente es el caso de uso más popular para adoptar agentes LLM. En operaciones internas, estos agentes pueden ahorrar entre un 30% y un 90% del tiempo dedicado a tareas rutinarias.
La atención automatizada permite responder consultas las 24 horas, proporcionar información consistente y personalizar la experiencia según el historial del cliente. En ventas, puedes utilizarlos para cualificar prospectos y recopilar información valiosa sin intervención humana.
Si tienes dudas sobre qué aplicación se adapta mejor a tu negocio, te recomendamos empezar con una prueba piloto en el área que más tiempo te consume actualmente.
¿Cómo se evalúa realmente un modelo LLM?
Si alguna vez te has preguntado cómo los investigadores determinan si un LLM es bueno o malo, aquí tienes la respuesta. Evaluar estos modelos no es tan sencillo como parece, y conocer estos métodos te ayudará a entender mejor qué significan realmente esas puntuaciones que ves en las comparativas.
La métrica de perplejidad: ¿qué tan “confundido” está el modelo?
La perplejidad es una de las formas más básicas de medir qué tan bien funciona un LLM. Piensa en ella como un medidor de “confusión” del modelo: cuanto más baja sea la puntuación, menos confundido está el modelo al predecir la siguiente palabra.
Te lo explicamos con un ejemplo sencillo. Si le das a un modelo la frase “El gato está durmiendo en el…” y puede predecir fácilmente que la siguiente palabra es “sofá”, tendrá una perplejidad baja. Si no tiene ni idea de qué viene después, la perplejidad será alta.
El proceso funciona calculando la probabilidad inversa del texto de prueba, normalizada por palabra. Cuando un modelo tiene mucha confianza en sus predicciones, obtienes números bajos que indican mejor rendimiento.
Recuerda que la perplejidad, aunque útil, no te dice todo sobre la calidad del modelo. Un modelo puede ser excelente prediciendo palabras pero terrible creando textos coherentes o creativos.
Benchmarks: las “pruebas de conducir” de los LLM
Para poder comparar modelos de forma justa, la comunidad científica ha desarrollado una serie de pruebas estandarizadas. Son como los exámenes de conducir, pero para inteligencias artificiales:
MMLU (Massive Multitask Language Understanding): Esta es la prueba más completa, con unas 16.000 preguntas de opción múltiple que cubren 57 materias diferentes, desde matemáticas hasta historia. Es como si hicieras que el modelo se examine de toda la carrera universitaria.
ARC (AI2 Reasoning Challenge): Contiene más de 7.700 preguntas de ciencias a nivel escolar, divididas en fáciles y difíciles. Perfecta para medir si el modelo puede razonar como un estudiante.
TruthfulQA: Esta prueba es especial porque mide si el modelo dice la verdad o inventa respuestas cuando no sabe algo. Muy útil para detectar esas “alucinaciones” de las que hablaremos más adelante.
También existen pruebas especializadas como HumanEval para programación, GSM8K para matemáticas y Chatbot Arena donde usuarios reales votan qué respuestas prefieren.
Una tendencia interesante son las evaluaciones “LLM-as-a-judge”, donde un modelo avanzado como GPT-4 actúa como juez para evaluar a otros modelos. El MT-Bench utiliza esta metodología para probar conversaciones de varios turnos.
Los problemas de las evaluaciones actuales
Aunque estas pruebas son útiles, tienen limitaciones importantes que debes conocer. Un estudio reciente de Apple demostró que el rendimiento de los LLM “se deteriora cuando aumenta la complejidad de las preguntas”. Los investigadores observaron que pequeños cambios en las preguntas pueden alterar completamente los resultados, lo que indica que estos modelos son “muy flexibles pero también muy frágiles”.
Otro problema serio es la “contaminación de datos”. Como los modelos se entrenan con textos de internet, existe el riesgo de que hayan “memorizado” las respuestas de las pruebas, invalidando los resultados. Es como si un estudiante hubiera visto el examen antes de hacerlo.
Además, los benchmarks se “saturan” rápidamente. Cuando los modelos más avanzados obtienen puntuaciones del 99%, ya no sirven para medir el progreso. Por eso han desarrollado pruebas más difíciles como MMLU-Pro, que incluye preguntas más complicadas y más opciones de respuesta.
La limitación más grande es que estas evaluaciones no miden aspectos cruciales como la empatía, creatividad o comprensión pragmática del lenguaje, que son fundamentales para aplicaciones del mundo real.
Si estás evaluando LLMs para tu empresa o proyecto, te recomendamos que no te guíes únicamente por estas puntuaciones. Las pruebas prácticas con casos de uso reales suelen ser más reveladoras que los benchmarks académicos.
Riesgos y limitaciones de los LLM actuales
Ya has visto las capacidades impresionantes de los LLM, pero también necesitas conocer sus limitaciones importantes. Estos modelos, aunque potentes, presentan desafíos significativos que debes tener en cuenta antes de implementarlos en aplicaciones sensibles.
Alucinaciones y generación de información falsa
¿Sabes qué son las alucinaciones en los modelos de lenguaje? Se trata de un fenómeno donde estos sistemas generan respuestas que suenan convincentes pero contienen información completamente falsa o inventada. Esto ocurre porque los LLM operan mediante predicción probabilística de palabras, priorizando que el texto suene coherente por encima de la veracidad de los hechos.
Un ejemplo que te ayudará a entender la gravedad del problema: un abogado utilizó ChatGPT para redactar un escrito legal con referencias generadas por la IA, solo para descubrir posteriormente que los casos legales citados no existían en absoluto, lo que resultó en sanciones por parte del juez.
Los datos son reveladores. Incluso los modelos más avanzados alucinan entre un 2,5% y 8,5% de las veces en tareas generales, cifra que puede superar el 15% en algunos modelos. En dominios especializados como el jurídico, la tasa de alucinaciones puede alcanzar entre el 69% y 88% de las respuestas.
Sesgos en los datos de entrenamiento
Los LLM heredan y amplifican los sesgos presentes en sus datos de entrenamiento. Puedes pensar en esto como si un estudiante aprendiera de libros que contienen prejuicios históricos – inevitablemente incorporará esas perspectivas sesgadas.
Te mostramos un ejemplo concreto: cuando preguntas a ChatGPT por posibles nombres de ejecutivos, el 60% de los nombres generados son masculinos, mientras que al solicitar nombres de profesores, la mayoría son femeninos. Esto revela cómo los modelos perpetúan estereotipos de género presentes en sus datos de entrenamiento.
Además, un estudio reciente descubrió que las respuestas de los principales modelos LLM tienden a alinearse con perfiles demográficos específicos: principalmente hombres, adultos, con alto nivel educativo y con interés en política.
Problemas de privacidad y seguridad
Cuando interactúas con los LLM, debes considerar los riesgos relacionados con la privacidad y seguridad de tu información. Al introducir datos en estos sistemas, existe el peligro de que esta información pueda ser almacenada, utilizada para futuros entrenamientos o, en el peor escenario, expuesta a terceros debido a vulnerabilidades de seguridad.
Las amenazas más críticas identificadas por OWASP incluyen:
- Inyección de prompts
- Manejo inseguro de salidas
- Envenenamiento de datos de entrenamiento
- Denegación de servicio del modelo
Estas vulnerabilidades podrían permitir a atacantes manipular el comportamiento del LLM para extraer información sensible o ejecutar código malicioso.
Un caso real que ilustra estos riesgos: empleados de Samsung compartieron información confidencial con ChatGPT mientras lo utilizaban para tareas laborales, exponiendo código y grabaciones de reuniones que potencialmente podrían hacerse públicos.
Recuerda que conocer estos riesgos no significa que debas evitar los LLM, sino que debes usarlos de manera informada y responsable.
Modelos LLM más importantes en 2025: ¿cuál elegir?
Image Source: Behind the Craft by Peter Yang
¿Te preguntas cuál es el mejor modelo LLM para tus proyectos? El panorama evoluciona constantemente, con nuevos modelos que mejoran las capacidades de sus antecesores. A continuación, te mostramos las opciones más destacadas para que puedas elegir la más adecuada según tus necesidades.
GPT-4, Claude 3 y Gemini 1.5: los líderes del mercado
Los modelos comerciales dominan actualmente el mercado gracias a sus capacidades avanzadas. GPT-4o de OpenAI destaca por su capacidad multimodal en tiempo real, procesando texto, imágenes y audio con una latencia mínima de aproximadamente 300 ms. Si necesitas un modelo para tareas que requieren respuestas rápidas y procesamiento multimedia, esta es una excelente opción.
Claude 3 Opus de Anthropic sobresale en tareas de razonamiento y resolución de problemas complejos, superando a GPT-4 en benchmarks como razonamiento experto de nivel graduado (GPQA) y matemáticas básicas (GSM8K). Te recomendamos Claude si trabajas con análisis profundos o necesitas resolver problemas que requieren lógica avanzada.
Por su parte, Gemini 1.5 Pro de Google ofrece capacidades impresionantes de análisis multimodal y puede procesar hasta 1 millón de tokens, permitiendo analizar documentos extensos o incluso horas de video. Es ideal si necesitas procesar grandes volúmenes de información de una sola vez.
Alternativas de código abierto: LLaMA 3, Mistral y DeepSeek
¿Prefieres tener control total sobre tus datos? Los modelos de código abierto avances rápidamente. LLaMA de Meta te permite instalar localmente versiones con diferentes tamaños de parámetros, manteniendo toda tu información en tu propio servidor.
Mistral destaca por su eficiencia y ofrece versiones optimizadas para funcionar tanto en CPU como en GPU. Si tienes recursos limitados pero necesitas un buen rendimiento, Mistral puede ser tu mejor opción.
DeepSeek ha ganado popularidad por su rendimiento excepcional en razonamiento y codificación, compitiendo directamente con modelos comerciales. La ventaja principal de estas alternativas gratuitas es que toda la información permanece en tu dispositivo, garantizando la privacidad completa de tus datos.
¿Cómo comparar parámetros y capacidad de tokens?
Las capacidades varían significativamente según la arquitectura de cada modelo. GPT-4o ofrece un contexto de 128.000 tokens, mientras que Gemini 1.5 Pro eleva este límite a 1 millón (con planes de expandirlo a 2 millones). Claude 3 Opus maneja hasta 200.000 tokens, permitiendo analizar documentos muy extensos.
Recuerda que el tamaño también importa: aunque las cifras exactas son confidenciales, se estima que GPT-4 contiene aproximadamente 1,8 billones de parámetros, mientras Gemini 1.5 Pro ronda los 1,5 billones y Claude Opus aproximadamente 200.000 millones de parámetros.
La elección del modelo adecuado dependerá de tus necesidades específicas: presupuesto, volumen de datos a procesar, nivel de privacidad requerido y tipo de tareas que realizarás.
¿Hacia dónde van los LLM? Las tendencias que marcarán el futuro
¿Te has preguntado cómo serán los LLM en los próximos años? La evolución de estos modelos avanza a un ritmo acelerado, y conocer las tendencias te ayudará a prepararte para los cambios que se avecinan.
Modelos que entienden todo: multimodalidad y contextos extensos
La tendencia más importante que verás es la integración multimodal. Los nuevos modelos como Gemini 1.5 y GPT-4o procesan simultáneamente texto, imágenes, audio y video, permitiendo interacciones más naturales y completas con el usuario. Esto significa que podrás subir una foto, hacer una pregunta de voz y recibir una respuesta escrita, todo en la misma conversación.
Además, la capacidad para manejar contextos extensos ha dado un salto extraordinario. Mientras que antes los modelos “olvidaban” información después de unas pocas páginas, ahora pueden procesar hasta 1 millón de tokens en Gemini, con planes de alcanzar 2 millones próximamente. Esto te permite analizar documentos completos, libros enteros o incluso horas de video sin perder el hilo de la conversación.
Modelos más eficientes: menos recursos, mejor rendimiento
Una tendencia que te beneficiará directamente es la cuantización. Esta técnica reduce la precisión numérica de los pesos del modelo, pasando de representaciones de 32 bits a formatos más compactos como INT8 o INT4. ¿Qué significa esto para ti? Modelos hasta 8 veces más pequeños, menor consumo energético y mayor velocidad de respuesta.
Modelos como DeepSeek-V3 demuestran que puedes obtener un rendimiento excepcional con costos significativamente menores. Si planeas usar LLM en tu empresa, esta tendencia te permitirá acceder a capacidades avanzadas sin necesidad de grandes inversiones en hardware.
Regulación: las nuevas reglas del juego
Recuerda que la Unión Europea ha promulgado la primera ley integral sobre IA, con aplicación gradual hasta 2026. Este marco clasifica los sistemas según su nivel de riesgo e impone obligaciones proporcionales, prohibiendo prácticas consideradas inaceptables. China, Canadá y otros países también desarrollan sus propios esquemas regulatorios.
¿Qué impacto tendrá esto en tu uso diario? Mayor transparencia en cómo funcionan los modelos, mejor protección de tus datos personales y estándares más altos de calidad y seguridad.
El equilibrio entre innovación y control responsable determinará qué tan rápido podrás acceder a estas nuevas capacidades y bajo qué condiciones.
Conclusión
¿Qué hemos aprendido sobre los LLM a lo largo de este recorrido? Principalmente, que estos modelos representan una tecnología extraordinaria que ya está cambiando la forma en que trabajamos y nos comunicamos.
Recuerda que los LLM funcionan procesando enormes cantidades de texto para aprender patrones del lenguaje humano. Su arquitectura basada en transformadores les permite entender el contexto y generar respuestas coherentes, aunque no siempre precisas.
En cuanto a las aplicaciones prácticas, puedes utilizarlos para generar contenido, resumir documentos, traducir textos o crear asistentes virtuales para tu negocio. La productividad que ofrecen es considerable: pueden ahorrar entre un 30% y 90% del tiempo en tareas rutinarias.
Sin embargo, ten en cuenta sus limitaciones importantes. Las alucinaciones ocurren entre el 2,5% y 15% de las veces, los sesgos están presentes en sus respuestas, y debes ser cauteloso con la información sensible que compartas.
Si vas a utilizar estos modelos de forma habitual, te recomendamos que:
• Evalúes tus necesidades específicas antes de elegir entre opciones comerciales como GPT-4o, Claude 3 o Gemini 1.5 • Consideres alternativas de código abierto como LLaMA o Mistral si necesitas mayor control sobre tus datos • Siempre verifiques la información importante que generen estos sistemas
El futuro apunta hacia modelos más eficientes, multimodales y con contextos más largos. La regulación también está llegando, especialmente en Europa.
Como usuario de estas tecnologías, tu comprensión de estos conceptos te permitirá aprovechar mejor su potencial mientras evitas sus riesgos principales. La clave está en usarlos como herramientas poderosas, pero siempre con supervisión y criterio humano.
Key Takeaways
Los LLM representan una revolución tecnológica que está transformando la forma en que interactuamos con las máquinas y procesamos información. Aquí están los puntos esenciales que debes conocer:
• Los LLM son modelos de IA especializados en lenguaje que utilizan arquitecturas Transformer para procesar billones de parámetros y generar texto similar al humano.
• Su entrenamiento requiere recursos masivos: GPT-3 consumió 1.287 MWh de electricidad y produjo más de 500 toneladas de CO2, equivalente a 600 vuelos transatlánticos.
• Las aplicaciones prácticas incluyen generación de contenido, traducción multilingüe, conversión de código y asistentes virtuales que ahorran 30-90% del tiempo en tareas rutinarias.
• Los principales riesgos son las alucinaciones (2,5-15% de respuestas falsas), sesgos heredados de datos de entrenamiento y vulnerabilidades de privacidad y seguridad.
• El futuro apunta hacia modelos multimodales más eficientes, contextos de hasta 2 millones de tokens y regulación responsable como la nueva ley europea de IA.
La comprensión de estas capacidades y limitaciones te permitirá aprovechar el potencial de los LLM mientras navegas responsablemente por este panorama tecnológico en constante evolución.
Recuerda que puedes utilizar toda la potencia los modelos llm en tus agentes de IA con n8n y utilizar sus modelos de procesamiento a tus flujos de trabajo.
FAQs
Q1. ¿Qué es exactamente un LLM y cómo funciona? Un LLM (Modelo de Lenguaje de Gran Tamaño) es un modelo de inteligencia artificial diseñado para comprender y generar lenguaje humano. Funciona analizando enormes conjuntos de datos textuales y utilizando redes neuronales profundas para aprender patrones lingüísticos y generar texto coherente.
Q2. ¿Cuáles son las aplicaciones prácticas más comunes de los LLM en 2025? Las aplicaciones más comunes incluyen la generación automática de contenido, traducción multilingüe, conversión de código entre lenguajes de programación y asistentes virtuales avanzados para atención al cliente y productividad empresarial.
Q3. ¿Cuáles son los principales riesgos asociados con el uso de LLM? Los riesgos más significativos son las alucinaciones (generación de información falsa), la perpetuación de sesgos presentes en los datos de entrenamiento y los problemas de privacidad y seguridad relacionados con el manejo de datos sensibles.
Q4. ¿Cómo se evalúa el rendimiento de un LLM? El rendimiento se evalúa mediante métricas como la perplejidad, que mide la capacidad predictiva del modelo, y benchmarks estandarizados que evalúan diferentes capacidades como comprensión, razonamiento y generación de texto. También se utilizan evaluaciones adversariales para probar la robustez del modelo.
Q5. ¿Cuáles son las tendencias futuras en el desarrollo de LLM? Las tendencias incluyen el desarrollo de modelos multimodales que integran texto, imagen y audio, la capacidad de manejar contextos más largos (hasta millones de tokens), técnicas de reducción de tamaño para mejorar la eficiencia, y un enfoque en la gobernanza y regulación responsable de estas tecnologías.






