


In diesem Artikel erfahren Sie auf praktische und einfache Weise alles, was Sie über Large Language Models (LLMs) wissen müssen. Sie erfahren, was sie genau sind, wie sie im Inneren funktionieren und was ihre wichtigsten Anwendungen im Jahr 2025 sind. Sie erfahren auch, welche Risiken Sie berücksichtigen sollten und wie Sie das für Ihre Bedürfnisse am besten geeignete Modell auswählen.
Wenn Sie sich jemals gefragt haben, wie ChatGPT, Claude oder Gemini Texte fast wie ein Mensch verstehen und generieren können, finden Sie hier die Antworten. Wir zeigen Ihnen alles, von den Grundlagen bis hin zu den fortschrittlichsten Trends, immer mit praktischen Beispielen, die Sie anwenden können.
Wichtige Punkte
LLMs stellen eine technologische Revolution dar, die die Art und Weise, wie wir mit Maschinen interagieren und Informationen verarbeiten, verändert. Hier sind die wesentlichen Punkte, die Sie wissen sollten:
• LLMs sind sprachspezialisierte KI-Modelle, die Transformer-Architekturen verwenden, um Billionen von Parametern zu verarbeiten und menschenähnlichen Text zu generieren.
• Die Ausbildung erfordert enorme Ressourcen: GPT-3 verbrauchte 1.287 MWh Strom und produzierte mehr als 500 Tonnen CO2, was 600 Transatlantikflügen entspricht.
• Zu den praktischen Anwendungen gehören die Erstellung von Inhalten, mehrsprachige Übersetzung, Codekonvertierung und virtuelle Assistenten, die 30-90 % der Zeit bei Routineaufgaben sparen.
• Die Hauptrisiken sind Halluzinationen (2,5-15 % der falschen Antworten), Verzerrungen, die von Trainingsdaten übernommen wurden, sowie Datenschutz- und Sicherheitslücken.
• Die Zukunft weist auf effizientere multimodale Modelle, Kontexte von bis zu 2 Millionen Token und eine verantwortungsvolle Regulierung wie das neue europäische KI-Gesetz hin.
Wenn Sie diese Fähigkeiten und Grenzen verstehen, können Sie das Potenzial von LLMs nutzen, während Sie sich verantwortungsbewusst in dieser sich ständig weiterentwickelnden technologischen Landschaft bewegen.
Was ist ein LLM oder “Large Language Model”?
Stellen Sie sich ein System vor, das Millionen von Büchern, Artikeln und Webseiten innerhalb weniger Tage lesen kann und dann all dieses Wissen nutzt, um Gespräche zu führen, Texte zu schreiben oder komplexe Probleme zu lösen. Das ist genau das, was ein Large Language Model tut.
Ein LLM ist eine Art von künstlicher Intelligenz, die auf das Verstehen und Generieren menschlicher Sprache spezialisiert ist. Im Gegensatz zu herkömmlichen Programmen, die bestimmten Regeln folgen, lernen diese Modelle Sprachmuster, indem sie große Textmengen analysieren. Das Ergebnis ist verblüffend: Sie können wie Menschen schreiben, Sprachen übersetzen, Code codieren oder Fragen zu praktisch jedem Thema beantworten.
Warum sind sie jetzt so wichtig? Weil sie einen Grad an Raffinesse erreicht haben, der es ihnen ermöglicht, Aufgaben auszuführen, die bisher nur von Menschen erledigt werden konnten. ChatGPT, Claude, Gemini… All diese Namen, die man ständig hört, sind Beispiele für LLMs, die die Art und Weise verändern, wie wir arbeiten, studieren und kommunizieren.
Was ist ein LLM oder “Large Language Model”?
Technische Definition von LLM
Ein Large Language Model (LLM) ist ein System der künstlichen Intelligenz, das mit riesigen Textmengen trainiert wird und die menschliche Sprache auf überraschend natürliche Weise verstehen und generieren kann. Stellen Sie es sich wie ein Programm vor, das Millionen von Büchern, Artikeln und Webseiten “gelesen” hat und nun Gespräche führen, Texte schreiben und Fragen konsistent beantworten kann.
Die technische Basis dieser Modelle sind Transformatoren, eine Architektur neuronaler Netze, die als ausgeklügeltes Aufmerksamkeitssystem funktioniert. Stellen Sie sich vor, Sie lesen einen Satz: Transformatoren können sich alle Wörter gleichzeitig “ansehen” und verstehen, wie sie miteinander in Beziehung stehen, anstatt sie einzeln zu verarbeiten, wie es frühere Systeme taten.
Während des Trainings lernen diese Systeme, vorherzusagen, welches Wort in einem Text als nächstes kommt, und entwickeln nach und nach ein tiefes Verständnis von Grammatik, Bedeutung und Kontext. Es ist ein Selbstlernprozess, bei dem das Modell sprachliche Muster entdeckt, ohne dass ihm jemand bestimmte Regeln beibringt.
Unterschied zwischen LLM und anderen KI-Modellen
Haben Sie sich jemals gefragt, was LLMs im Vergleich zu anderen Arten von künstlicher Intelligenz besonders macht? Der Hauptunterschied liegt in ihrer Spezialisierung und Fokussierung.
Während KI ein weit gefasster Begriff ist, der jedes System umfasst, das menschliche Fähigkeiten nachahmt, konzentrieren sich LLMs ausschließlich auf die Sprache. Andere KI-Modelle sind möglicherweise darauf ausgelegt, Bilder zu erkennen, Markttrends vorherzusagen oder Roboter zu steuern, aber LLMs sind nur Experten für das Verstehen und Generieren von Text.
Zu den wichtigsten Unterschieden gehören:
- Sprachspezialisierung: LLMs meistern Aufgaben wie Übersetzen, Zusammenfassen oder Schreiben, während sich andere KI-Modelle auf völlig andere Bereiche wie Computer Vision oder Datenanalyse konzentrieren.
- Spezifische Architektur: Sie verwenden optimierte Transformatoren, um Beziehungen zwischen Wörtern zu erkennen, etwas, das andere Arten von KI nicht unbedingt erfordern.
- Generative Fähigkeiten: Viele LLMs können Originalinhalte erstellen, obwohl generative KI mehr als nur Text umfasst, einschließlich Bilder, Musik und Code.
Warum werden sie als “große” Sprachmodelle bezeichnet?
Der Begriff “groß” ist kein Werbehype. Er verweist auf drei Aspekte, die in ihrer Größe wirklich beeindruckend sind:
Parametergröße: LLMs enthalten Billionen von Parametern, die wie die “internen Anpassungen” sind, die bestimmen, wie sie funktionieren. Um Ihnen eine Vorstellung von der Größenordnung zu geben: GPT-3 hat 175.000 Millionen Parameter, während Jurassic-1 178.000 Millionen hat. Es ist, als hätten sie Millionen von kleinen Entscheidungen in sich programmiert.
Menge an Trainingsdaten: Diese Modelle haben riesige Mengen an Text aus dem Internet verarbeitet. Die Rede ist von Common Crawl mit mehr als 50.000 Millionen Webseiten und Wikipedia mit 57 Millionen Artikeln. Das sind mehr Informationen, als irgendjemand in mehreren Leben lesen könnte.
Rechenkapazität: Für die Ausbildung eines LLM sind Supercomputer erforderlich, die wochen- oder monatelang arbeiten. Jeder dieser Billionen von Parametern muss fein abgestimmt werden, was eine außergewöhnliche Rechenleistung erfordert.
Zu den bekanntesten Modellen, die Sie derzeit verwenden können, gehören:
- GPT von OpenAI, bekannt für seine Argumentationsfähigkeit und kohärenten Antworten
- Claude , der sehr lange Dokumente mit bis zu 100.000 Token analysieren kann
- Meta Flame , optimiert für praktische, reale Anwendungen
- Google DeepMind’s Gemini, bereits integriert in Gmail und andere Dienste, die Sie wahrscheinlich täglich nutzen
Jeder hat besondere Stärken, aber sie alle teilen diese “große” Eigenschaft, die sie so mächtig im Umgang mit menschlicher Sprache macht.
Architektur von LLM-Modellen: Wie sie aufgebaut sind
Haben Sie sich jemals gefragt, was hinter der Fähigkeit von ChatGPT steckt, eine kohärente Konversation zu führen? In diesem Abschnitt erfahren Sie, wie diese Systeme von innen aufgebaut sind. Wir zeigen Ihnen auf einfache Weise die Hauptkomponenten, die es LLMs ermöglichen, Text so zu verstehen und zu generieren, als wären sie Menschen.
Denken Sie daran, dass die Architektur zwar auf den ersten Blick komplex erscheinen mag, aber wenn Sie sie verstehen, können Sie besser auswählen, welches Modell Sie entsprechend Ihren Anforderungen verwenden möchten.
Tiefe neuronale Netze und Aufmerksamkeitsschichten
LLMs arbeiten über mehrschichtige neuronale Netze, die in gewisser Weise die Funktionsweise des menschlichen Gehirns nachahmen. Stellen Sie sich diese Netzwerke als eine Reihe miteinander verbundener Filter vor, in denen jede Schicht die von der vorherigen Schicht empfangenen Informationen verarbeitet und verfeinert.
Der Hauptunterschied zu herkömmlichen Modellen ist die Anzahl der Schichten. Während alte Systeme eine oder zwei Schichten verwendeten, verwenden heutige LLMs Hunderte oder sogar Tausende von Schichten zur Verarbeitung von Informationen. Jeder Knoten in diesen Schichten hat eine bestimmte Gewichtung und einen Schwellenwert, der bestimmt, ob er aktiviert werden und Informationen an die nächste Schicht übergeben soll.
Innerhalb dieser Architektur finden Sie drei Haupttypen von Ebenen:
- Einbetten von Layern: Konvertieren Sie Wörter in Zahlen, die das Modell verstehen kann
- Aufmerksamkeitsebenen: Helfen Sie dem Modell, zu erkennen, welche Teile des Textes am wichtigsten sind
- Forward Feed Layers: Verarbeiten Sie all diese Informationen, um die endgültige Antwort zu generieren
Transformatoren und Selbstfürsorge
Hier passiert die Magie wirklich. Die Transformers, die 2017 vorgestellt wurden, haben das Spiel komplett verändert. Diese Architektur ermöglicht es dem Modell, alle Wörter in einem Satz gleichzeitig und nicht Wort für Wort zu verarbeiten.
Der Self-Care-Mechanismus ist das Herzstück dieser Technologie. Es funktioniert, indem es die Beziehung zwischen jedem Wort und allen anderen Wörtern im Text auswertet. In dem Satz “Der Hund im Park bellt laut” versteht das System beispielsweise “bellt” so, dass es sich auf “Hund” und nicht auf “Park” bezieht.
Diese Fähigkeit, Fernbeziehungen zu verstehen, war für frühere Modelle sehr schwierig. Darüber hinaus ist das Training durch die parallele Verarbeitung viel schneller und effizienter.
Transformatoren verwenden zwei Hauptkomponenten: einen Encoder, der den Eingabetext versteht, und einen Decoder, der die Antwort erzeugt. Einige Modelle, wie z. B. GPT, verwenden jedoch nur den Decoder-Teil.
Tokenisierung und Einbettungen
Bevor LLMs einen Text verarbeiten, müssen sie ihn mithilfe der Tokenisierung in Zahlen umwandeln. Bei diesem Prozess wird Text in kleine Einheiten unterteilt, die als Token bezeichnet werden.
Die am häufigsten verwendete Methode ist das Byte Pair Encoding (BPE), das die häufigsten Buchstabenkombinationen identifiziert und in Token umwandelt. Dies ermöglicht es dem Modell, mit neuen Wörtern, Eigennamen und sogar Tippfehlern intelligent umzugehen.
Nach der Tokenisierung wird jedes Wort in einen numerischen Vektor umgewandelt, der als Einbettung bezeichnet wird. Diese Vektoren erfassen die Bedeutung von Wörtern so, dass ähnliche Wörter ähnliche Zahlen haben.
Da Transformers alles gleichzeitig verarbeiten, müssen sie die Reihenfolge der Wörter kennen. Zu diesem Zweck verwenden sie Positionscodierungen, die jeder Einbettung hinzugefügt werden. Das Modell versteht also, dass “Maria liebt John” etwas anderes ist als “John liebt Mary”.
Wenn Sie Fragen zu diesen technischen Konzepten haben, empfehlen wir Ihnen, mit den praktischsten Aspekten zu beginnen und dann je nach Ihren spezifischen Bedürfnissen in die Details einzutauchen.
Training eines LLM-Modells: Wie viel kostet es wirklich?
Das Erstellen eines großen Sprachmodells ist nicht wie das Installieren eines Programms auf Ihrem Computer. Es ist ein Prozess, der enorme Ressourcen verbraucht und bestimmt, ob das Modell nützlich ist oder nicht. Hier finden Sie alles, was Sie über diesen Prozess wissen müssen.
Wie lernen LLMs? Zwei Hauptmethoden
Es gibt zwei Hauptmethoden, um diese Modelle zu trainieren, jede mit ihren eigenen Vorteilen:
Autoregressives Vortraining: Modelle wie GPT funktionieren wie ein Satzvervollständigungssystem. Sie lernen, anhand aller vorherigen Wörter vorherzusagen, was das nächste Wort sein wird. Es ist, als würde man auf seinem Handy tippen und es schlägt das nächste Wort vor.
Maskiertes Vortraining: Modelle wie BERT verwenden eine andere Methode. Zufällige Wörter werden in einem Text versteckt und das Modell muss erraten, welche fehlen. Es ist, als würde man eine Übung machen, um die Lücken zu füllen.
Der Hauptunterschied besteht darin, dass autoregressive Modelle nur zurückblicken, um Vorhersagen zu treffen, während maskierte Modelle sowohl rückwärts als auch vorwärts schauen können, um ein umfassenderes Verständnis des Kontexts zu erlangen.
Die realen Kosten: Zahlen, die Sie überraschen werden
Die Ausbildung zum LLM ist außerordentlich teuer. Um Ihnen eine klare Vorstellung zu geben:
Massiver Energieverbrauch: GPT-3 benötigte 1.287 MWh Strom für seine Ausbildung. Das entspricht dem Jahresverbrauch von mehr als 100 Haushalten.
Signifikanter CO2-Fußabdruck: Der Prozess erzeugte mehr als 500 Tonnen CO2, vergleichbar mit 600 Flügen zwischen New York und London oder dem, was 38 spanische Haushalte in einem ganzen Jahr produzieren.
Hohe wirtschaftliche Investitionen:
- Ein Modell mit 1.500 Millionen Parametern kostete 2020 0,95 Millionen Euro
- GPT-3 (175 Milliarden Parameter) kostete rund 3,82 Milliarden Euro
- GPT-4 überstieg aufgrund seiner höheren Komplexität 95,42 Millionen Euro
Denken Sie daran, dass diese Kosten in zwei Phasen unterteilt sind: Die Erstschulung verbraucht 20-40% der Gesamtenergie, findet aber nur einmal statt. Die Phase der kontinuierlichen Nutzung kann 50-60 % des langfristigen Energieverbrauchs ausmachen.
Wussten Sie, dass die Generierung von Bildern 2,907 kWh pro 1.000 Vorgänge verbraucht, während die Generierung von Text nur 0,047 kWh benötigt? Die Textgenerierung ist wesentlich effizienter.
Wie lernen sie ohne menschliche Aufsicht?
Selbstüberwachtes Lernen ist der Schlüssel zu erfolgreichen LLMs. Im Gegensatz zu herkömmlichen Methoden, die manuell beschriftete Daten benötigen, generieren diese Modelle ihre eigenen Beschriftungen aus Rohtext.
Der Prozess funktioniert so: Das Modell lernt, fehlende Teile des Textes oder das nächste Wort in einer Sequenz vorherzusagen. Auf diese Weise können Sie mit großen Textmengen aus dem Internet trainieren, ohne dass manuelles Tagging erforderlich ist.
Der Prozess gliedert sich in zwei Phasen:
Schritt 1: Pretexting-Aufgaben – Das Modell lernt Repräsentationen von Sprache durch Aufgaben wie das Vorhersagen versteckter Wörter oder das Abschließen von Sequenzen.
Schritt 2: Spezifische Aufgaben – Die gelernten Repräsentationen werden auf bestimmte Aufgaben wie Übersetzung oder Textklassifizierung angewendet.
Es gibt zwei Haupttechniken:
- Selbstprädiktives Lernen: Das Modell prognostiziert Teile von Daten auf der Grundlage anderer Teile
- Kontrastives Lernen: Das Modell lernt, Beziehungen zwischen verschiedenen Datenstichproben zu unterscheiden
Diese Methodik ermöglicht es, die massiven Rechenressourcen, die zur Erstellung immer leistungsfähigerer LLMs erforderlich sind, effizient zu nutzen.
Praktische Anwendungen von LLMs im Jahr 2025
LLMs sind nicht mehr nur Laborexperimente. Bis 2025 lösen diese Tools reale Probleme in Unternehmen aller Branchen. Hier sind die nützlichsten Apps, die Sie heute bereitstellen können.
Automatische Textgenerierung und Zusammenfassungen
Müssen Sie große Mengen an Informationen schnell verarbeiten? LLMs zeichnen sich durch ihre Fähigkeit aus, originelle Inhalte zu erstellen und lange Dokumente zusammenzufassen, während wichtige Punkte beibehalten werden.
Durch das Erstellen automatischer Zusammenfassungen können Sie bei der Verarbeitung von Informationen viel Zeit und Ressourcen sparen. Diese Funktionalität ist besonders wertvoll für:
- Forschungsartikel und technische Dokumentationen
- Rechtliche und finanzielle Dokumente
- Kundenfeedback Trendanalyse
- Geschäftsberichte und Marktforschung
Es gibt zwei Hauptmethoden, die Sie verwenden können. Die extraktive Zusammenfassung identifiziert und extrahiert die relevantesten Sätze aus dem Originaltext, während die abstrakte Zusammenfassung neue Sätze generiert, die die Essenz des Inhalts erfassen. Je nach Bedarf erhalten Sie alles von kurzen Zusammenfassungen bis hin zu detaillierten Analysen.
Fortschrittlichere Tools bieten auch Ranking-Scores, um die Relevanz extrahierter Sätze zu bewerten, und Positionsinformationen, um die wichtigsten Elemente zu lokalisieren.
Mehrsprachige Übersetzung und Codekonvertierung
Wenn Sie mit mehreren Sprachen arbeiten oder alten Code modernisieren müssen, bieten LLMs präzise Lösungen, die herkömmliche Methoden übertreffen.
Bei der Übersetzung erfassen diese Modelle kulturelle Nuancen und bewahren den Ton des Originaltextes. Das DeepL-Modell übertrifft ChatGPT-4, Google und Microsoft in der Qualität und erfordert deutlich weniger Überarbeitungen: Während Google doppelt so viele Korrekturen und ChatGPT-4 dreimal benötigt, um die gleiche Qualität zu erreichen.
In Bezug auf die Codekonvertierung haben sich LLMs bei der Migration von Legacy-Systemen als außerordentlich effektiv erwiesen. Das CodeScribe-Tool zum Beispiel kombiniert promptes Engineering mit menschlicher Überwachung, um Fortran-Code effizient in C++ zu konvertieren.
Die Ergebnisse sind beeindruckend: Während Sie vor dem Einsatz von LLM 2-3 Dateien pro Tag konvertieren konnten, steigt die Produktivität mit diesen Tools auf 10-12 Dateien pro Tag.
Virtuelle Assistenten und Business-Chatbots
Möchten Sie den Kundenservice automatisieren oder interne Prozesse verbessern? LLM-gestützte Assistenten sorgen für flüssige Gespräche, verstehen komplexe Fragen und passen sich an den Stil jedes Benutzers an.
Denken Sie daran, dass es einen wichtigen Unterschied gibt: KI-Assistenten sind reaktiv und führen Aufgaben bei Bedarf aus, während KI-Agenten proaktiv sind und autonom arbeiten, um bestimmte Ziele zu erreichen.
Eine Studie unter 167 Unternehmen identifizierte den Kundenservice als den beliebtesten Anwendungsfall für die Einführung von LLM-Agenten. Im internen Betrieb können diese Agenten 30 % bis 90 % der Zeit einsparen, die für Routineaufgaben aufgewendet wird.
Der automatisierte Support ermöglicht es Ihnen, Anfragen 24 Stunden am Tag zu beantworten, konsistente Informationen bereitzustellen und das Erlebnis auf der Grundlage der Kundenhistorie zu personalisieren. Im Vertrieb können Sie sie nutzen, um potenzielle Kunden zu qualifizieren und wertvolle Informationen ohne menschliches Eingreifen zu sammeln.
Wenn Sie sich nicht sicher sind, welche App für Ihr Unternehmen am besten geeignet ist, empfehlen wir Ihnen, mit einem Pilottest in dem Bereich zu beginnen, der derzeit die meiste Zeit in Anspruch nimmt.
Wie evaluiert man eigentlich ein LLM-Modell?
Wenn Sie sich jemals gefragt haben, wie Forscher feststellen, ob ein LLM gut oder schlecht ist, finden Sie hier die Antwort. Die Auswertung dieser Modelle ist nicht so einfach, wie es sich anhört, und wenn Sie diese Methoden kennen, können Sie besser verstehen, was die Ergebnisse, die Sie in den Vergleichen sehen, wirklich bedeuten.
Die Verwirrungsmetrik: Wie “verwirrt” ist das Modell?
Ratlosigkeit ist eine der grundlegendsten Methoden, um zu messen, wie gut ein LLM funktioniert. Betrachten Sie es als eine Modell-“Verwirrungs”-Anzeige: Je niedriger die Punktzahl, desto weniger verwirrt ist das Modell bei der Vorhersage des nächsten Wortes.
Wir erklären es Ihnen anhand eines einfachen Beispiels. Wenn Sie einem Model den Satz “Die Katze schläft in der…” Und Sie können leicht vorhersagen, dass das nächste Wort “Couch” ist, Sie werden wenig ratlos sein. Wenn Sie keine Ahnung haben, was als nächstes kommt, wird die Ratlosigkeit groß sein.
Der Prozess funktioniert durch Berechnung der inversen Wahrscheinlichkeit des Testtextes, normiert pro Wort. Wenn ein Modell sehr zuversichtlich in seinen Vorhersagen ist, erhalten Sie niedrige Zahlen, die auf eine bessere Leistung hinweisen.
Denken Sie daran, dass Verwirrung zwar nützlich ist, Ihnen aber nicht alles über die Qualität des Modells sagt. Ein Modell kann großartig darin sein, Wörter vorherzusagen, aber schrecklich darin, kohärente oder kreative Texte zu erstellen.
Benchmarks: Die “Fahrtests” von LLMs
Um Modelle fair vergleichen zu können, hat die wissenschaftliche Gemeinschaft eine Reihe von standardisierten Tests entwickelt. Sie sind wie Fahrprüfungen, nur für künstliche Intelligenz:
MMLU (Massive Multitask Language Understanding): Dies ist der umfassendste Test mit etwa 16.000 Multiple-Choice-Fragen zu 57 verschiedenen Fächern, von Mathematik bis Geschichte. Es ist, als hätte man das Modell während der gesamten universitären Laufbahn untersuchen lassen.
ARC (AI2 Reasoning Challenge): Enthält mehr als 7.700 naturwissenschaftliche Fragen auf Schulniveau, unterteilt in leicht und schwer. Perfekt, um zu messen, ob das Modell wie ein Student denken kann.
TruthfulQA: Dieser Test ist etwas Besonderes, weil er misst, ob das Modell die Wahrheit sagt oder Antworten erfindet, wenn es etwas nicht weiß. Sehr nützlich, um die “Halluzinationen” zu erkennen, über die wir später sprechen werden.
Es gibt auch spezialisierte Tests wie HumanEval für die Programmierung, GSM8K für Mathematik und Chatbot Arena , bei denen echte Benutzer darüber abstimmen, welche Antworten sie bevorzugen.
Ein interessanter Trend sind “LLM-as-a-Judge”-Bewertungen, bei denen ein fortschrittliches Modell wie GPT-4 als Richter fungiert, um andere Modelle zu bewerten. Die MT-Bench verwendet diese Methodik, um Multi-Turn-Konversationen zu testen.
Die Probleme mit aktuellen Evaluierungen
Diese Tests sind zwar nützlich, haben aber wichtige Einschränkungen, die Sie beachten sollten. Eine aktuelle Studie von Apple zeigte, dass sich die Leistung von LLMs “verschlechtert, wenn die Komplexität der Fragen zunimmt”. Die Forscher stellten fest, dass kleine Änderungen in den Fragen die Ergebnisse völlig verändern können, was darauf hindeutet, dass diese Modelle “sehr flexibel, aber auch sehr fragil” sind.
Ein weiteres ernstzunehmendes Problem ist die “Datenkontamination”. Da die Modelle mit Texten aus dem Internet trainiert werden, besteht die Gefahr, dass sie sich die Antworten der Tests “eingeprägt” haben und die Ergebnisse ungültig werden. Es ist, als hätte ein Schüler die Prüfung gesehen, bevor er sie gemacht hat.
Zudem sind Benchmarks schnell “gesättigt”. Wenn die fortschrittlichsten Modelle 99 % erreichen, sind sie für die Messung des Fortschritts nicht mehr nützlich. Aus diesem Grund haben sie schwierigere Tests wie MMLU-Pro entwickelt, die kompliziertere Fragen und mehr Antwortmöglichkeiten enthalten.
Die größte Einschränkung besteht darin, dass diese Bewertungen entscheidende Aspekte wie Empathie, Kreativität oder pragmatisches Sprachverständnis nicht messen, die für reale Anwendungen entscheidend sind.
Wenn Sie LLMs für Ihr Unternehmen oder Projekt auswerten, empfehlen wir Ihnen, sich nicht ausschließlich auf diese Bewertungen zu verlassen. Praktische Tests mit realen Anwendungsfällen sind oft aufschlussreicher als akademische Benchmarks.
Risiken und Grenzen aktueller LLMs
Sie haben bereits die beeindruckenden Fähigkeiten von LLMs gesehen, aber Sie müssen auch ihre wichtigen Grenzen kennen. Diese Modelle sind zwar leistungsstark, stellen jedoch erhebliche Herausforderungen dar, die Sie berücksichtigen sollten, bevor Sie sie für vertrauliche Anwendungen bereitstellen.
Halluzinationen und Erzeugung falscher Informationen
Wissen Sie, was Halluzinationen in Sprachmodellen sind? Es ist ein Phänomen, bei dem diese Systeme Antworten generieren, die überzeugend klingen, aber völlig falsche oder erfundene Informationen enthalten. Dies geschieht, weil LLMs mit probabilistischen Wortvorhersagen arbeiten und der Kohärenz des Textes Vorrang vor der Richtigkeit der Fakten einräumen.
Ein Beispiel, das Ihnen hilft, den Ernst des Problems zu verstehen: Ein Anwalt nutzte ChatGPT, um einen Schriftsatz mit KI-generierten Referenzen zu verfassen, nur um später festzustellen, dass die zitierten Rechtsfälle überhaupt nicht existierten, was zu Strafen des Richters führte.
Die Daten sind aufschlussreich. Selbst die fortschrittlichsten Modelle halluzinieren zwischen 2,5 % und 8,5 % der Zeit bei allgemeinen Aufgaben, eine Zahl, die bei einigen Modellen 15 % überschreiten kann. In spezialisierten Bereichen wie dem Recht kann die Rate der Halluzinationen zwischen 69 % und 88 % der Reaktionen liegen.
Verzerrungen in Trainingsdaten
LLMs erben und verstärken die in ihren Trainingsdaten vorhandenen Verzerrungen. Sie können sich das so vorstellen, dass ein Schüler aus Büchern lernt, die historische Vorurteile enthalten – sie werden unweigerlich diese voreingenommenen Perspektiven einbeziehen.
Hier ist ein konkretes Beispiel: Wenn Sie ChatGPT nach möglichen Namen von Führungskräften fragen, sind 60 % der generierten Namen männlich, während bei der Abfrage von Lehrernamen die meisten weiblich sind. Dies zeigt, wie die Modelle Geschlechterstereotypen aufrechterhalten, die in ihren Trainingsdaten vorhanden sind.
Darüber hinaus ergab eine kürzlich durchgeführte Studie, dass die Antworten der wichtigsten LLM-Modelle tendenziell mit spezifischen demografischen Profilen übereinstimmen: hauptsächlich Männer, Erwachsene, hoch gebildet und mit Interesse an Politik.
Datenschutz- und Sicherheitsfragen
Wenn Sie mit LLMs interagieren, sollten Sie die Risiken im Zusammenhang mit dem Datenschutz und der Sicherheit Ihrer Daten berücksichtigen. Bei der Eingabe von Daten in diese Systeme besteht die Gefahr, dass diese Informationen gespeichert, für zukünftige Trainings verwendet oder im schlimmsten Fall aufgrund von Sicherheitslücken Dritten zugänglich gemacht werden.
Zu den kritischsten Bedrohungen, die von OWASP identifiziert wurden, gehören:
- Prompte Injektion
- Unsichere Abwicklung von Abgängen
- Vergiftung von Trainingsdaten
- Modell-Denial-of-Service
Diese Sicherheitsanfälligkeiten könnten es Angreifern ermöglichen, das Verhalten des LLM zu manipulieren, um vertrauliche Informationen zu extrahieren oder bösartigen Code auszuführen.
Ein realer Fall, der diese Risiken veranschaulicht: Samsung-Mitarbeiter teilten vertrauliche Informationen mit ChatGPT, während sie es für Arbeitsaufgaben verwendeten, und legten Code und Aufzeichnungen von Besprechungen offen, die möglicherweise veröffentlicht werden könnten.
Denken Sie daran, dass das Wissen um diese Risiken nicht bedeutet, dass Sie LLMs vermeiden sollten, sondern dass Sie sie auf informierte und verantwortungsvolle Weise nutzen sollten.
Die wichtigsten LLM-Modelle im Jahr 2025: Welches soll man wählen?
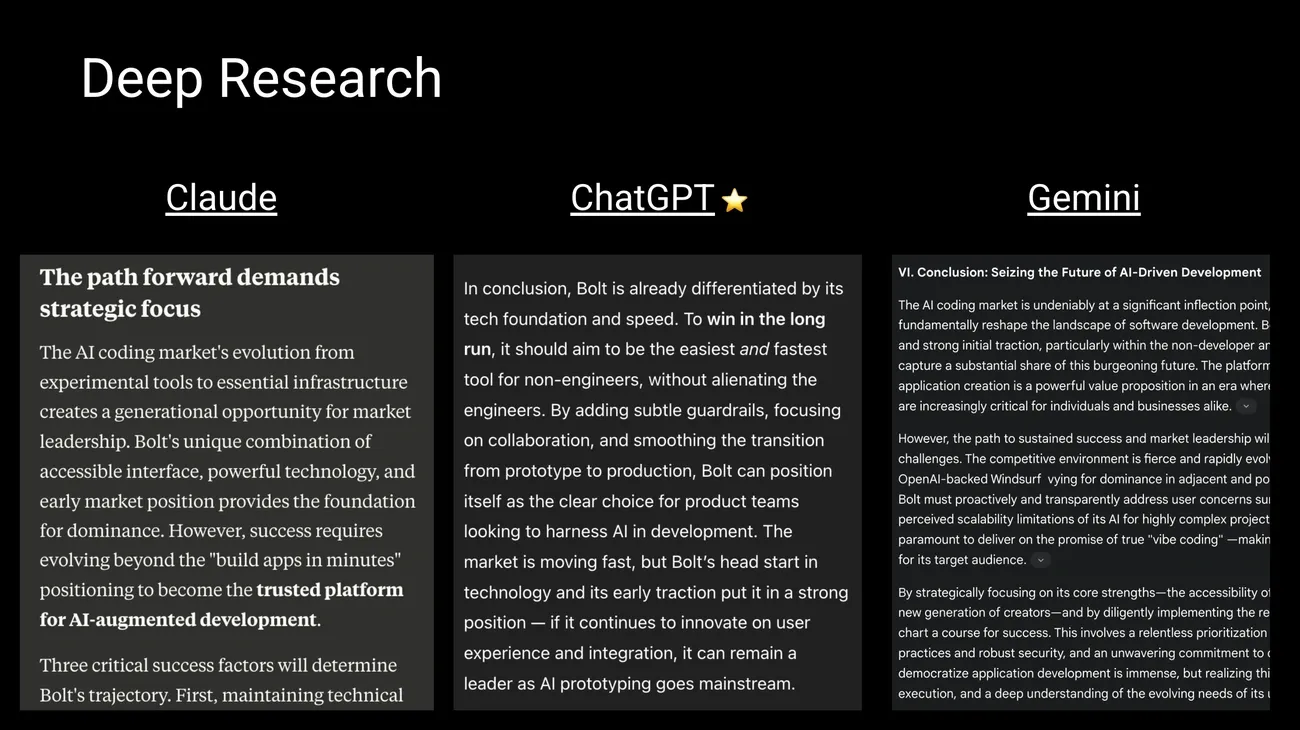
Bildquelle: Behind the Craft von Peter Yang
Sie fragen sich, welches LLM-Modell für Ihre Projekte am besten geeignet ist? Die Landschaft entwickelt sich ständig weiter, wobei neue Modelle die Fähigkeiten ihrer Vorgänger verbessern. Im Folgenden zeigen wir Ihnen die herausragendsten Optionen, damit Sie die für Ihre Bedürfnisse am besten geeignete auswählen können.
GPT-4, Claude 3 und Gemini 1.5: die Marktführer
Geschäftsmodelle dominieren derzeit den Markt dank ihrer fortschrittlichen Fähigkeiten. GPT-4o von OpenAI zeichnet sich durch seine multimodale Echtzeitfähigkeit aus und verarbeitet Text, Bilder und Audio mit einer minimalen Latenz von etwa 300 ms. Wenn Sie ein Modell für Aufgaben benötigen, die schnelle Antworten und Medienverarbeitung erfordern, ist dies eine gute Option.
Das Claude 3 Opus von Anthropic zeichnet sich durch komplexe Denk- und Problemlösungsaufgaben aus und übertrifft GPT-4 in Benchmarks wie Expert Reasoning (GPQA) und Basic Mathematics (GSM8K). Wir empfehlen Claude, wenn Sie mit tiefer Analyse arbeiten oder Probleme lösen müssen, die eine fortgeschrittene Logik erfordern.
Googles Gemini 1.5 Pro bietet beeindruckende multimodale Analysefunktionen und kann bis zu 1 Million Token verarbeiten, sodass Sie lange Dokumente oder sogar stundenlange Videos analysieren können. Es ist ideal, wenn Sie große Mengen an Informationen auf einmal verarbeiten müssen.
Open-Source-Alternativen: LLaMA 3, Mistral und DeepSeek
Sie bevorzugen die volle Kontrolle über Ihre Daten? Open-Source-Modelle entwickeln sich rasant weiter. LLaMA von Meta ermöglicht es Ihnen, Versionen mit unterschiedlichen Parametergrößen lokal zu installieren und alle Ihre Informationen auf Ihrem eigenen Server zu behalten.
Mistral zeichnet sich durch seine Effizienz aus und bietet Versionen, die sowohl für die Ausführung auf CPU als auch auf GPU optimiert sind. Wenn Sie nur über begrenzte Ressourcen verfügen, aber eine gute Leistung benötigen, ist Mistral möglicherweise die beste Option.
DeepSeek hat aufgrund seiner außergewöhnlichen Leistung beim Denken und Codieren an Popularität gewonnen und konkurriert direkt mit kommerziellen Modellen. Der Hauptvorteil dieser kostenlosen Alternativen besteht darin, dass alle Informationen auf Ihrem Gerät verbleiben, wodurch der vollständige Schutz Ihrer Daten gewährleistet ist.
Wie vergleicht man Parameter und Token-Kapazität?
Die Funktionen variieren je nach Architektur des jeweiligen Modells erheblich. GPT-4o bietet einen Kontext von 128.000 Token, während Gemini 1.5 Pro dieses Limit auf 1 Million anhebt (mit Plänen, es auf 2 Millionen zu erweitern). Claude 3 Opus verarbeitet bis zu 200.000 Token, sodass Sie sehr große Dokumente analysieren können.
Denken Sie daran, dass auch die Größe eine Rolle spielt: Obwohl die genauen Zahlen vertraulich sind, wird geschätzt, dass GPT-4 etwa 1,8 Billionen Parameter enthält, während Gemini 1.5 Pro etwa 1,5 Billionen und Claude Opus etwa 200.000 Millionen Parameter enthält.
Die Wahl des richtigen Modells hängt von Ihren spezifischen Anforderungen ab: Budget, Volumen der zu verarbeitenden Daten, erforderlicher Datenschutz und Art der Aufgaben, die Sie ausführen werden.
Wohin gehen LLMs? Die Trends, die die Zukunft prägen werden
Haben Sie sich jemals gefragt, wie LLMs in den kommenden Jahren aussehen werden? Die Entwicklung dieser Modelle schreitet in rasantem Tempo voran, und die Kenntnis der Trends wird Ihnen helfen, sich auf die kommenden Veränderungen vorzubereiten.
Modelle, die alles verstehen: Multimodalität und umfangreiche Zusammenhänge
Der wichtigste Trend, den Sie sehen werden, ist die multimodale Integration. Neue Modelle wie Gemini 1.5 und GPT-4o verarbeiten gleichzeitig Text, Bilder, Audio und Video und ermöglichen so eine natürlichere und vollständigere Interaktion mit dem Benutzer. Das bedeutet, dass Sie in der Lage sein werden, ein Foto hochzuladen, eine Sprachfrage zu stellen und eine schriftliche Antwort zu erhalten, und das alles im selben Gespräch.
Darüber hinaus hat die Fähigkeit, mit großen Zusammenhängen umzugehen, einen außergewöhnlichen Sprung gemacht. Während Modelle früher Informationen nach ein paar Seiten “vergessen” haben, können sie jetzt bis zu 1 Million Token auf Gemini verarbeiten, mit Plänen, bald 2 Millionen zu erreichen. Auf diese Weise können Sie ganze Dokumente, ganze Bücher oder sogar stundenlange Videos analysieren, ohne den roten Faden des Gesprächs zu verlieren.
Effizientere Modelle: weniger Ressourcen, bessere Leistung
Ein Trend, von dem Sie direkt profitieren werden, ist die Quantisierung. Diese Technik reduziert die numerische Genauigkeit der Gewichtungen des Modells und wechselt von 32-Bit-Darstellungen zu kompakteren Formaten wie INT8 oder INT4. Was bedeutet das für Sie? Modelle bis zu 8-mal kleiner, geringerer Stromverbrauch und schnellere Reaktionsgeschwindigkeit.
Modelle wie DeepSeek-V3 beweisen, dass Sie außergewöhnliche Leistung zu deutlich geringeren Kosten erzielen können. Wenn Sie planen, LLM in Ihrem Unternehmen einzusetzen, ermöglicht Ihnen dieser Trend den Zugriff auf erweiterte Funktionen, ohne große Investitionen in Hardware tätigen zu müssen.
Verordnung: die neuen Spielregeln
Er erinnert daran, dass die Europäische Union das erste umfassende Gesetz über KI erlassen hat, das bis 2026 schrittweise umgesetzt wird. Dieser Rahmen klassifiziert die Systeme nach ihrem Risikoniveau und erlegt verhältnismäßige Verpflichtungen auf, indem sie als inakzeptabel erachtete Praktiken verbieten. China, Kanada und andere Länder entwickeln ebenfalls ihre eigenen Regulierungssysteme.
Welche Auswirkungen wird dies auf Ihren täglichen Gebrauch haben? Mehr Transparenz in der Funktionsweise der Modelle, besserer Schutz Ihrer persönlichen Daten und höhere Qualitäts- und Sicherheitsstandards.
Das Gleichgewicht zwischen Innovation und verantwortungsvoller Kontrolle bestimmt, wie schnell und unter welchen Bedingungen Sie auf diese neuen Funktionen zugreifen können.
Fazit
Was haben wir auf diesem Weg über LLMs gelernt? In erster Linie, dass diese Modelle eine außergewöhnliche Technologie darstellen, die bereits die Art und Weise, wie wir arbeiten und kommunizieren, verändert.
Denken Sie daran, dass LLMs riesige Textmengen verarbeiten, um Muster in der menschlichen Sprache zu lernen. Ihre transformatorbasierte Architektur ermöglicht es ihnen, den Kontext zu verstehen und konsistente, wenn auch nicht immer genaue Antworten zu generieren.
In der Praxis können Sie sie verwenden, um Inhalte zu generieren, Dokumente zusammenzufassen, Texte zu übersetzen oder virtuelle Assistenten für Ihr Unternehmen zu erstellen. Die Produktivität, die sie bieten, ist beträchtlich: Sie können zwischen 30 % und 90 % der Zeit bei Routineaufgaben einsparen.
Seien Sie sich jedoch der wichtigen Einschränkungen bewusst. Halluzinationen treten in 2,5 bis 15 % der Fälle auf, ihre Antworten sind verzerrt und Sie sollten vorsichtig mit den sensiblen Informationen sein, die Sie teilen.
Wenn Sie diese Modelle regelmäßig verwenden, empfehlen wir Folgendes:
• Bewerten Sie Ihre spezifischen Bedürfnisse, bevor Sie sich zwischen kommerziellen Optionen wie GPT-4o, Claude 3 oder Gemini 1.5 entscheiden • Ziehen Sie Open-Source-Alternativen wie LLaMA oder Mistral in Betracht, wenn Sie mehr Kontrolle über Ihre Daten benötigen • Überprüfen Sie immer die wichtigen Informationen, die von diesen Systemen generiert werden
Die Zukunft weist auf effizientere, multimodale Modelle mit längeren Kontexten hin. Auch die Regulierung wird kommen, vor allem in Europa.
Als Nutzer dieser Technologien können Sie durch Ihr Verständnis dieser Konzepte ihr Potenzial besser nutzen und gleichzeitig die Hauptrisiken vermeiden. Der Schlüssel liegt darin, sie als mächtige Werkzeuge zu nutzen, aber immer mit menschlicher Aufsicht und Urteilsvermögen.
Wichtige Erkenntnisse
LLMs stellen eine technologische Revolution dar, die die Art und Weise, wie wir mit Maschinen interagieren und Informationen verarbeiten, verändert. Hier sind die wesentlichen Punkte, die Sie wissen sollten:
• LLMs sind sprachspezialisierte KI-Modelle, die Transformer-Architekturen verwenden, um Billionen von Parametern zu verarbeiten und menschenähnlichen Text zu generieren.
• Die Ausbildung erfordert enorme Ressourcen: GPT-3 verbrauchte 1.287 MWh Strom und produzierte mehr als 500 Tonnen CO2, was 600 Transatlantikflügen entspricht.
• Zu den praktischen Anwendungen gehören die Erstellung von Inhalten, mehrsprachige Übersetzung, Codekonvertierung und virtuelle Assistenten, die 30-90 % der Zeit bei Routineaufgaben sparen.
• Die Hauptrisiken sind Halluzinationen (2,5-15 % der falschen Antworten), Verzerrungen, die von Trainingsdaten übernommen wurden, sowie Datenschutz- und Sicherheitslücken.
• Die Zukunft weist auf effizientere multimodale Modelle, Kontexte von bis zu 2 Millionen Token und eine verantwortungsvolle Regulierung wie das neue europäische KI-Gesetz hin.
Wenn Sie diese Fähigkeiten und Grenzen verstehen, können Sie das Potenzial von LLMs nutzen, während Sie sich verantwortungsbewusst in dieser sich ständig weiterentwickelnden technologischen Landschaft bewegen.
Denken Sie daran, dass Sie mit n8n die volle Leistungsfähigkeit der llm-Modelle in Ihren KI-Agenten nutzen und deren Verarbeitungsmodelle für Ihre Workflows verwenden können.
FAQs
Frage 1. Was genau ist ein LLM und wie funktioniert er? Ein LLM (Large Language Model) ist ein Modell der künstlichen Intelligenz, das entwickelt wurde, um menschliche Sprache zu verstehen und zu generieren. Es funktioniert durch die Analyse riesiger Textdatensätze und die Verwendung tiefer neuronaler Netze, um linguistische Muster zu lernen und kohärenten Text zu generieren.
Frage 2. Was sind die häufigsten praktischen Anwendungen von LLM im Jahr 2025? Zu den gängigsten Anwendungen gehören die automatische Generierung von Inhalten, mehrsprachige Übersetzungen, Codekonvertierung zwischen Programmiersprachen und fortschrittliche virtuelle Assistenten für den Kundenservice und die Unternehmensproduktivität.
Frage 3. Was sind die Hauptrisiken, die mit der Verwendung von LLM verbunden sind? Die größten Risiken sind Halluzinationen (Generierung falscher Informationen), die Aufrechterhaltung von Verzerrungen in Trainingsdaten sowie Datenschutz- und Sicherheitsprobleme im Zusammenhang mit dem Umgang mit sensiblen Daten.
Frage 4. Wie wird die Leistung eines LLM bewertet? Die Leistung wird anhand von Metriken wie Perplexity bewertet, die die Vorhersagefähigkeit des Modells messen, und standardisierten Benchmarks, die verschiedene Fähigkeiten wie Verständnis, Argumentation und Textgenerierung bewerten. Adversarial Evaluations werden auch verwendet, um die Robustheit des Modells zu testen.
Frage 5. Was sind die zukünftigen Trends in der LLM-Entwicklung? Zu den Trends gehören die Entwicklung multimodaler Modelle, die Text, Bild und Audio integrieren, die Fähigkeit, längere Kontexte (bis zu Millionen von Token) zu verarbeiten, Downsizing-Techniken zur Verbesserung der Effizienz und ein Fokus auf verantwortungsvolle Governance und Regulierung dieser Technologien.






